Blog Feedhttps://www.bytecho.net2025-06-21T08:07:00.000Z欢迎试用 TodoListhttps://www.bytecho.net/archives/2394.html2025-06-21T08:07:00.000Z### 介绍
YuelaiEngine系列软件 - TodoList
「融合式协作/待办中心」,由 Gin + Element Plus 驱动。
### 项目特性
* 前后端分离架构,简易化部署,仅需一行命令
* 多样化待办清单,合作共享,Todo也能玩出花样
* 多维度待办清单,前端可设计的待办清单
* 邮件待办提醒,让待办不遗忘
* 合作待办清单,一起协作一项任务
* 共享待办清单,分享目前进度
* 支持 Markdown 的待办日志,记录每一次进步
* 待办清单截止锁定能力,不再错过DDL
* 大语言模型能力,一键生成待办清单
* 在线选号组件,简易而不失趣味
* 基于 RedisStream 轻量消息队列
* 轻量静态资源能力
### 技术说明
**「项目后端侧」消息队列感谢 redmq 提供思路。**
**「项目前端侧」侧边栏部分样式由大模型生成,与本项目设计无关!**
### 测试地址
https://todo.yuelaigroup.com:8500
### 网络要求
仅用于测试,故没有部署至云服务器,**需要IPv6**。
### 提议
反馈至评论区。
Docker Desktop修改默认存储路径https://www.bytecho.net/archives/2324.html2023-09-16T05:06:00.000Z### 前言
最近二开了不少项目,基本都是用Docker部署,所以之前在电脑上装了Docker,不过在 Windows 上安装 Docker Desktop 后,Docker默认是把镜像保存到 `C:\Users\<用户>\AppData\Local\Docker\wsl\data\` 路径的`ext4.vhdx`文件下,在C盘放这些无关紧要的文件属实是浪费,所以整理了一下方法,把这些文件移动到其他磁盘去。
### 修改WSL
首次启动 Docker Desktop 会提示安装 WSL,没有WSL则无法启动 Docker Engine 服务。因为目前的 docker 依附 WSL 来进行文件映射,所以通过 WSL 来修改 docker 的文件映射路径,就可以把这些文件移动到其他磁盘中。
> 默认情况下,Docker Desktop for Window 会创建如下两个发行版:
>
> 1. docker-desktop (distro/ext4.vhdx)
> 2. docker-desktop-data (data/ext4.vhdx)
目前WSL2已经全量发布,WSL2 下 docker-desktop-data 通常位于以下位置: `C:\Users\<你当前用户名>\AppData\Local\Docker\wsl\data\ext4.vhdx`,我电脑中这个文件夹高达`50GB+`,完全是浪费C盘空间!
在开始操作前,请先退出Docker Desktop,然后在terminal中输入`wsl --list -v`,确保两个服务都是停止状态:

#### 备份镜像
分别输入以下命令备份WSL,后面的备份路径可以自行修改,我这里是备份到了G磁盘:
```sh
wsl --export docker-desktop G:\docker-desktop.tar
wsl --export docker-desktop-data G:\docker-desktop-data.tar
```
#### 取消注册
```sh
wsl --unregister docker-desktop
wsl --unregister docker-desktop-data
```
#### 备份导入
执行命令前,请先更改命令中的`G:\docker-desktop.tar`,`G:\docker-desktop-data.tar`为自己之前备份的路径,挂载的路径`G:\docker\desktop`,`G:\docker\data`也需要改为自己想要挂载的路径(需提前创建好对应的文件夹,不然会提示找不到目录):
```sh
wsl --import docker-desktop "G:\docker\desktop" "G:\docker-desktop.tar" --version 2
wsl --import docker-desktop-data "G:\docker\data" "G:\docker-desktop-data.tar" --version 2
```
### 测试
输入`wsl --list -v`查看其输出是否和修改之前一样,正常情况下会出现两个发行版,即:`docker-desktop`,`docker-desktop-data`。
然后启动你的Docker Desktop看看是否能够正常运行。之后制作或者拉取的镜像都会存储在新的目录,而不是C盘中的默认路径。
### Docker清理缓存
最后再搬运一个清理docker缓存的教程~
> 在使用 docker build 构建镜像时,Docker 会按照 Dockerfile 中定义的步骤逐步生成 Docker 镜像。而镜像生成的过程中,每一步骤所生成的结果都会被缓存(cache)下来,以便下次镜像生成时不必再重新执行同一步骤以提高构建镜像的速度。
#### 使用 --no-cache
```
docker build --no-cache .
```
#### 使用 docker system prune
使用 `docker system prune` 命令来清理不再使用的资源,包括停止的容器、未被标记的镜像、未使用的网络和未使用的数据卷。
```
# 清理所有不再使用的资源
docker system prune
# 清理更加彻底,将未使用 Docker 镜像都删掉
docker system prune -a
```
---
Henry 23-09-16
流程中心 使用指南https://www.bytecho.net/archives/2316.html2023-09-06T15:07:00.000Z### 前言
很早之前就想让网站的某些操作自动化,今天终于实现了,话不多说,直接介绍吧。
本站工作流系统基于Ferry二次开发,采用Gin + ElementUI(Vue)前后端分离技术,集工单统计、任务钩子、权限管理、灵活设计流程与模版等能力于一身的开源工单系统。
项目二次开发源码已发布到:[Github项目仓库](https://www.bytecho.net/repository.html)
<div class="link-box">
<a href="https://work.yuelaigroup.com/" class="no-underline" title="进入流程中心" target="_blank" >
<div class="content"><p class="title">进入流程中心</p></div>
</a>
<a href="https://www.bytecho.net/account/register.php" class="no-underline" title="前往后台注册" target="_blank" >
<div class="content"><p class="title">前往后台注册</p></div>
</a>
</div>
### 登录流程
```mermaid
graph TD;
A["注册当前平台账号"] --> B["等待账号同步<br>(等待时间小于1分钟)"];
B --> C["进入流程中心"];
C --> D["使用注册时的账号和初始密码<br>(注册时所用的邮箱)登录"];
D -->|登录成功| E["发起工单申请"];
D -->|失败/忘记密码| F["联系管理员"];
F --> C;
```
### 如何登录(请以实际页面为准)
首先在[字节星球](https://www.bytecho.net/account/register.php)或其它已接入的平台注册一个账号(若已注册,请直接登录),由于流程中心与主站独立且暂未使用LDAP,所以需要等待系统将账号信息同步至流程中心(**该过程通常小于1分钟**),然后进入[流程中心首页](https://work.yuelaigroup.com/):
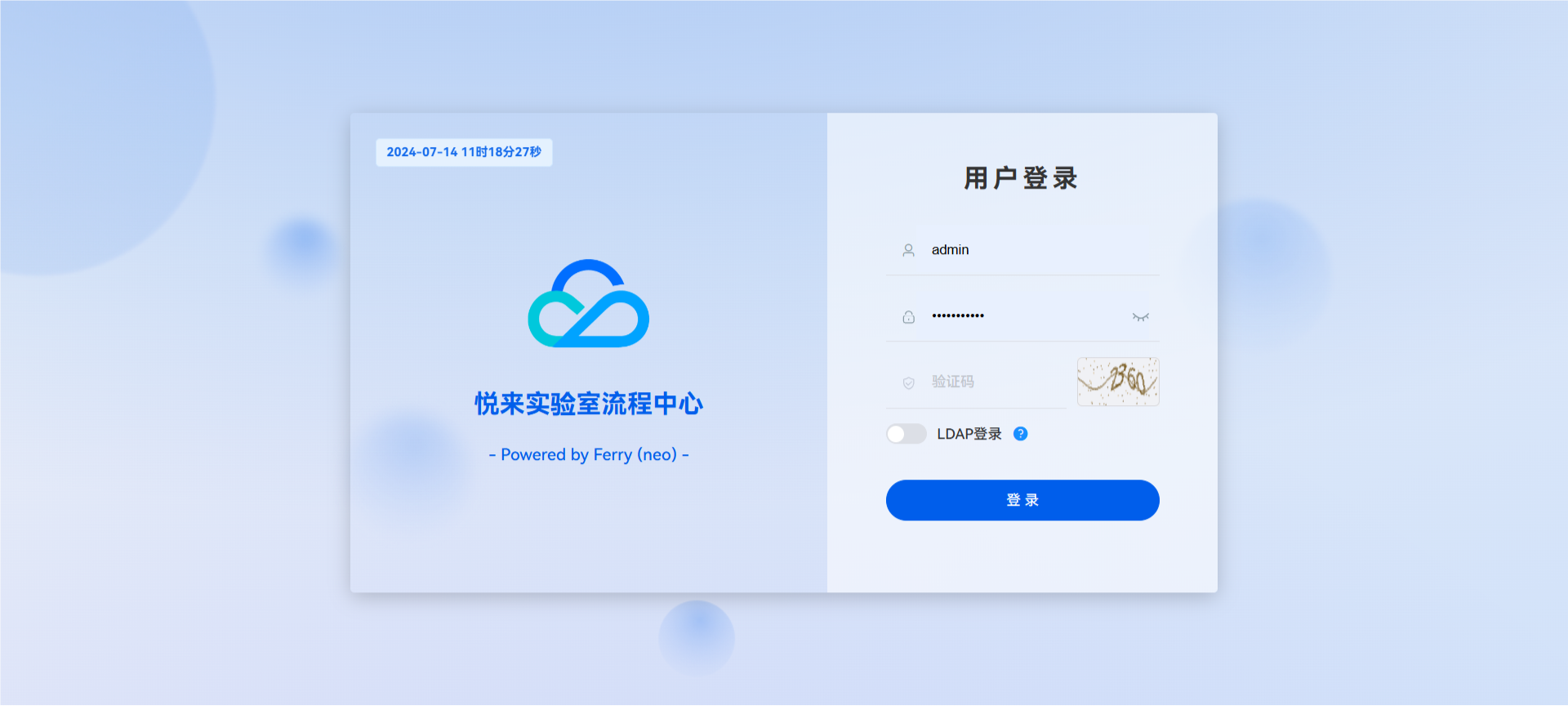
[tip type="info" title="初始账号信息"]
**用户账号:同对应平台的账号/用户名**
**初始密码:注册时所用的邮箱**
[/tip]
目前支持的平台有[字节星球](https://www.bytecho.net)和[陌上花博客](https://moshanghua.net)。下面以字节星球账号为例:
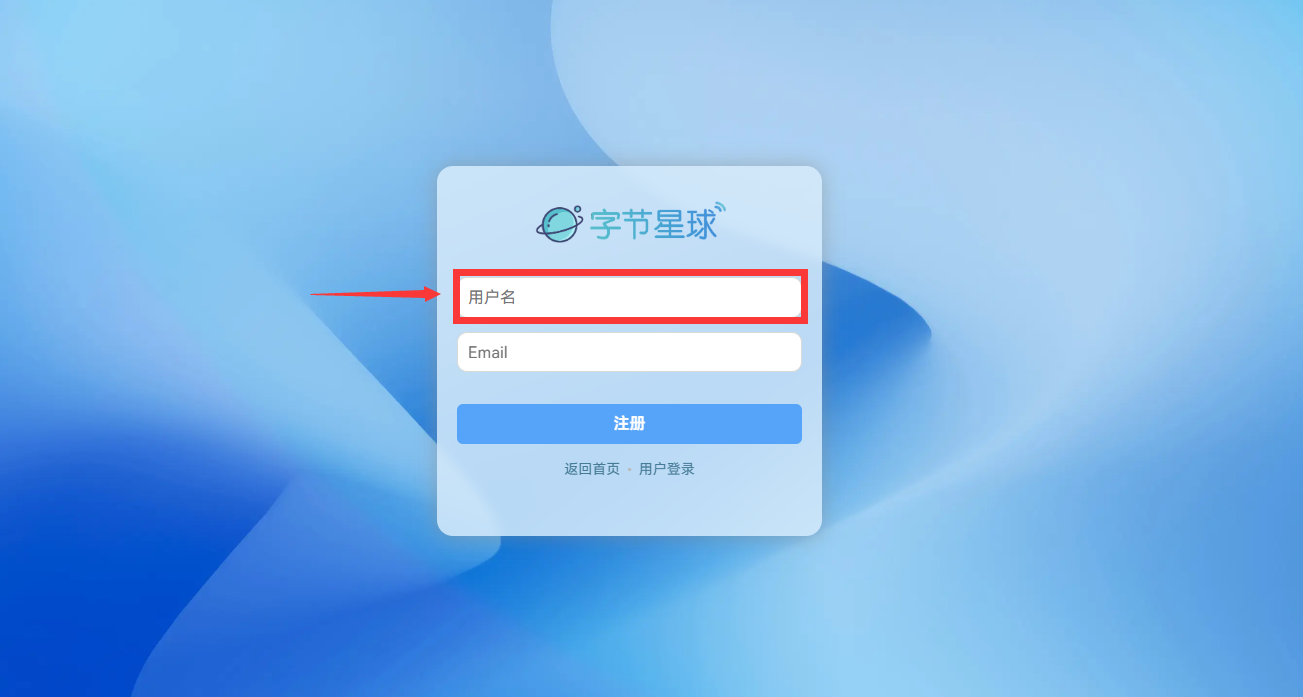
[tip type="danger"]
**用户名处所填写的内容才是你的账号,请勿将下方的Email作为账号,该Email仅用作邮件提醒。**
[/tip]
[tip type="warning"]
**首次进入系统后,请及时更改初始密码!请勿使用中文或符号作为用户名,避免登录失败!**
[/tip]
### 使用流程
```mermaid
graph TD;
E["发起工单申请"] --> G["有待处理工单吗?"];
G -->|是| H["处理当前工单"];
H --> I["是否还有待处理工单?"];
I -->|是| G;
I -->|否| J["流程结束"];
G -->|否| J;
```
### 如何使用
使用方式很简单,点击工单系统,进入工单申请,选择需要申请的项目,按照表单提示填写后,即可发起申请。
下图以友情链接申请为例:
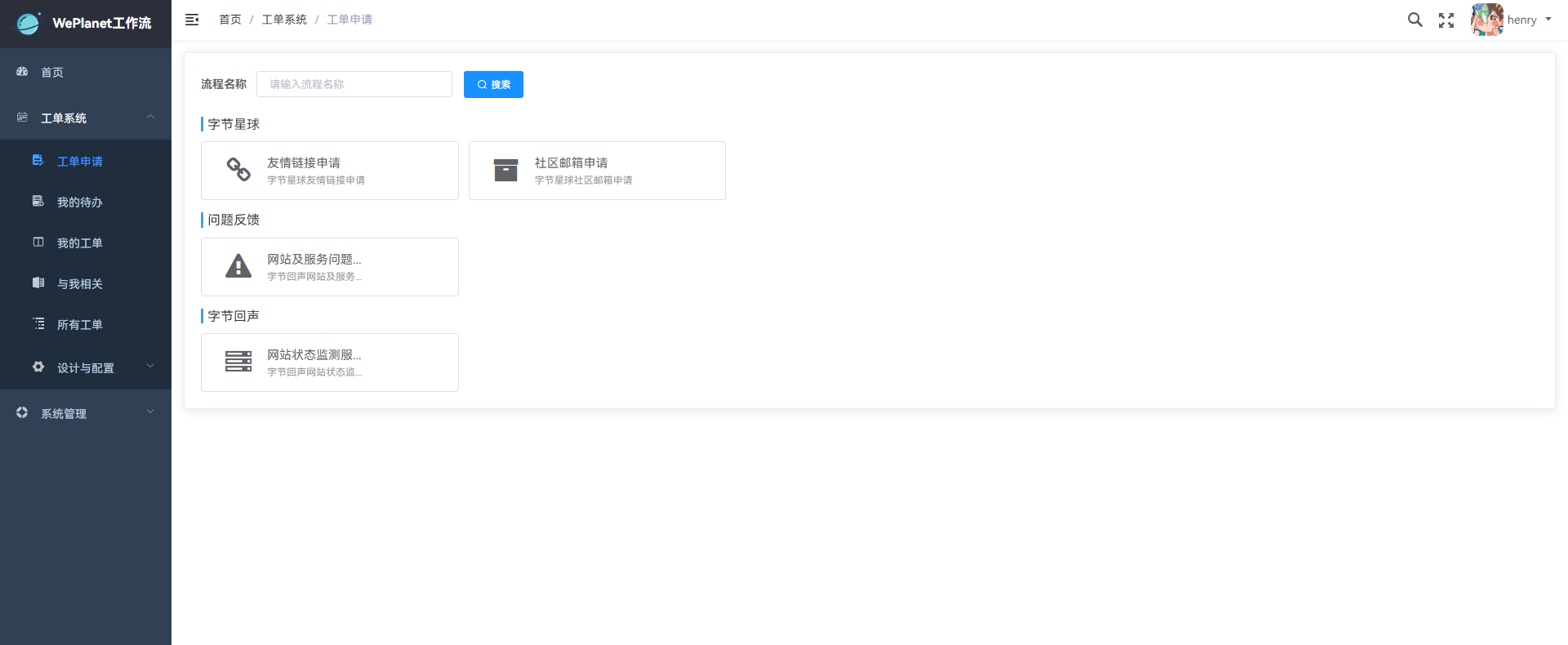
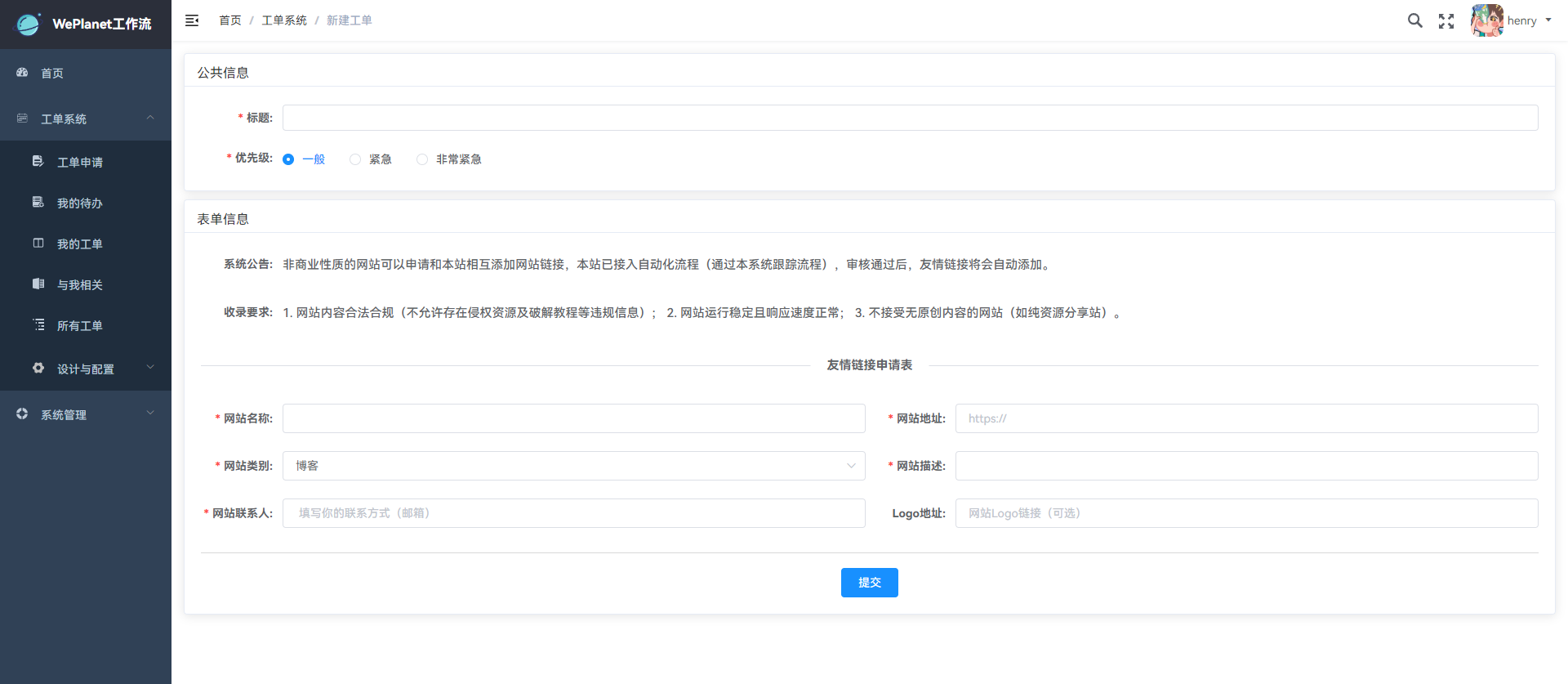
发起申请后,点击工单系统,进入我的工单,实时跟踪流程进度,直到流程结束。
**本系统已接入邮件提醒,所以在注册账号时请务必填写正确的邮箱**,字节星球账号所绑定的邮箱会同步到工作流系统,请注意来自`noreply#yuelaigroup.com`的邮件。
### 流程跟踪
通常一个工单流程有多个步骤,可能有需要申请人处理的流程,则需点击工单系统,进入**我的待办**,处理流转到自己的工单,是否有需要自己处理的工单请留意邮件提醒~
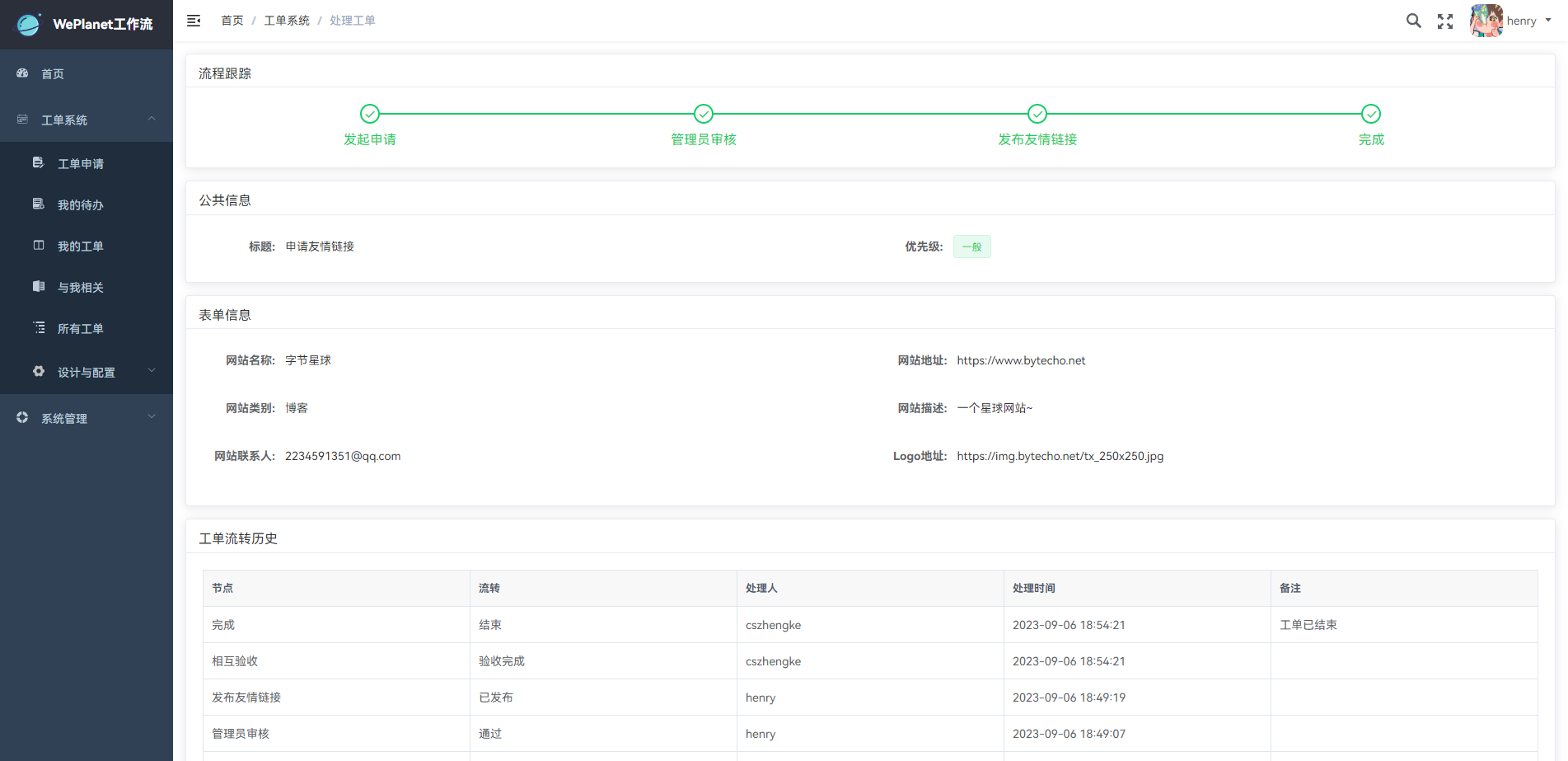
正在流转中的工单:
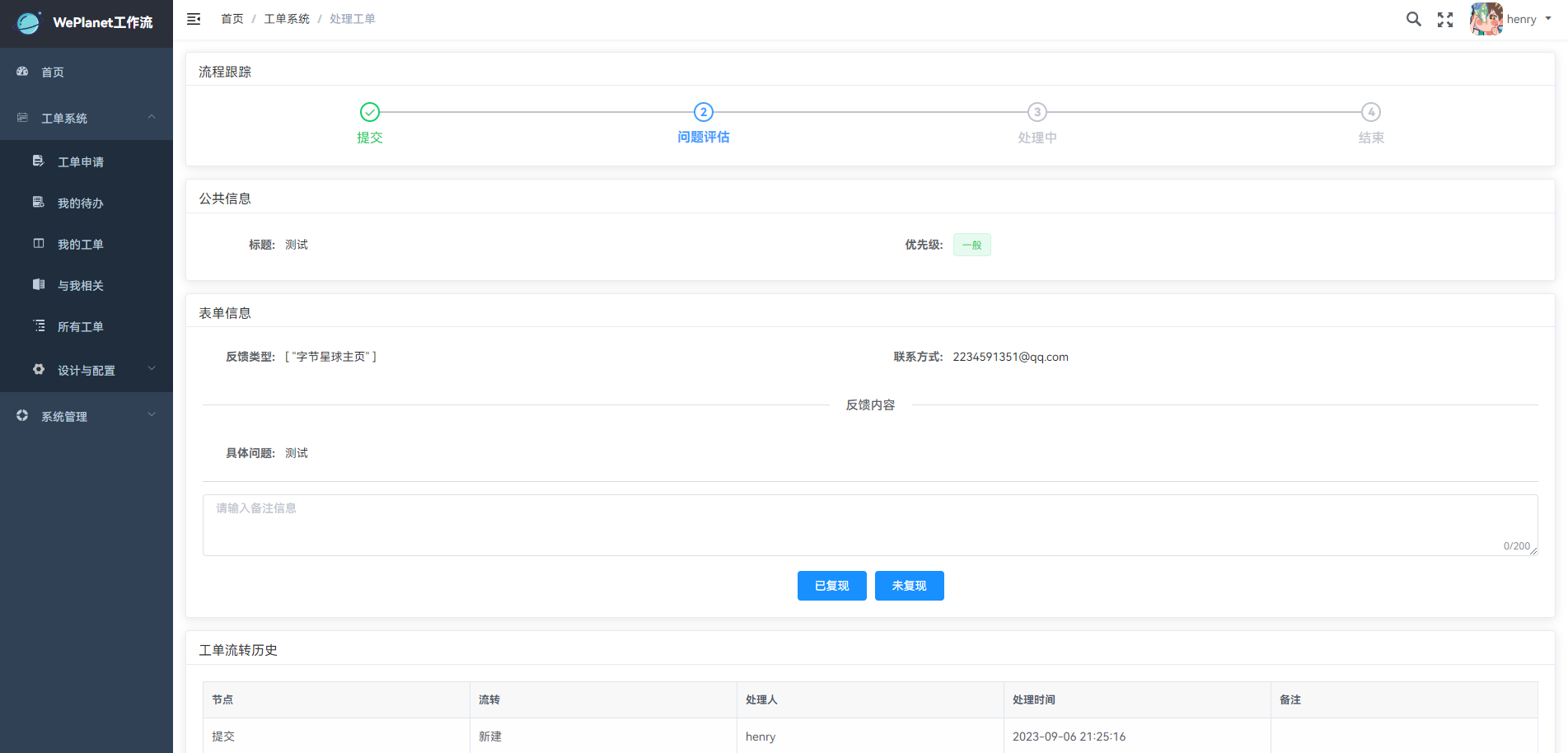
已完成的工单:
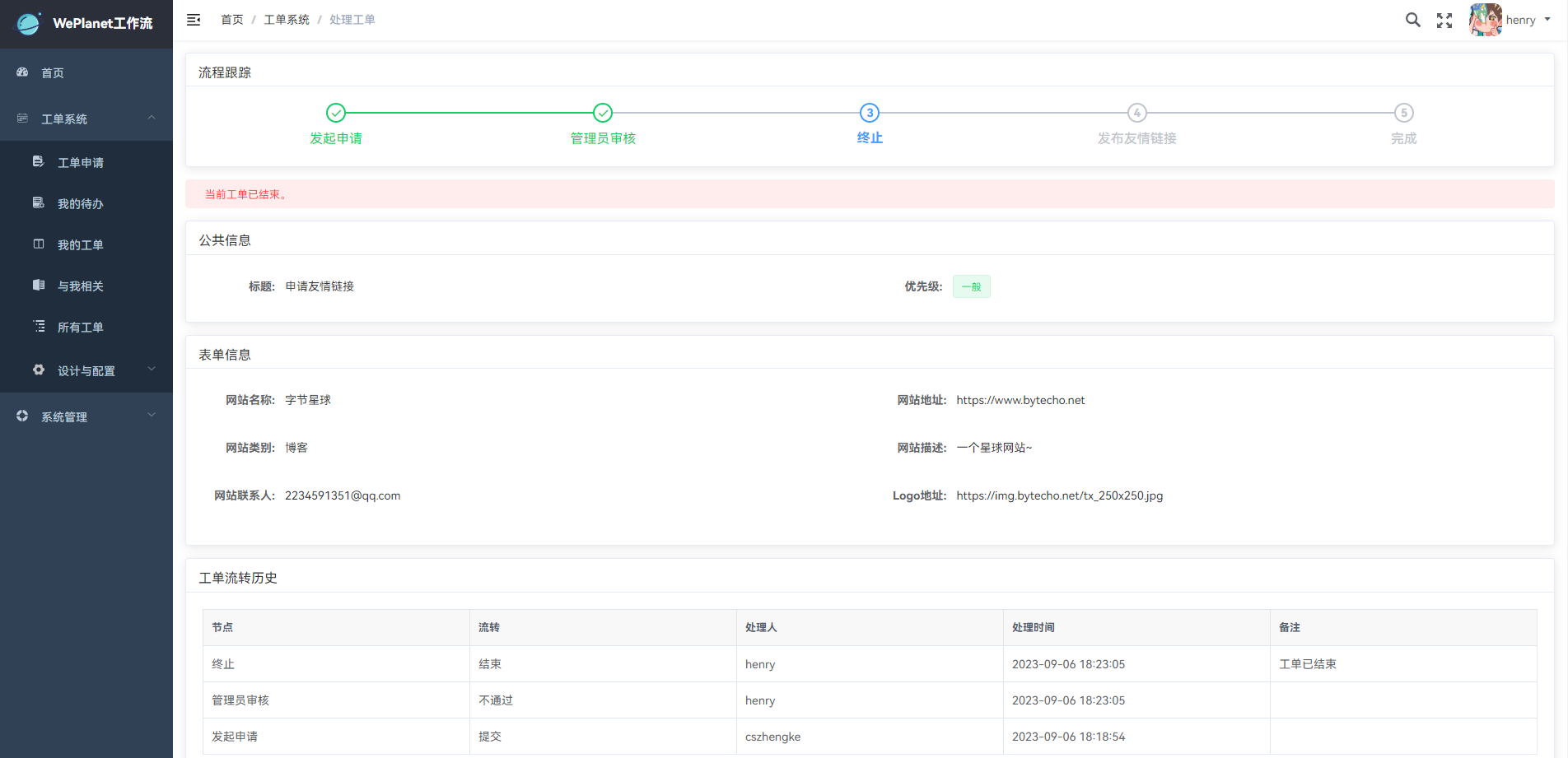
不通过而流程终止的工单:
### 已接入的板块
[友情链接](https://www.bytecho.net/links.html)与[星球认证](https://www.bytecho.net/archives/group.html)现已接入流程中心,申请表审核通过后,系统自动添加友情链接/认证信息,无需人工干预,后续会陆续将其他板块接入流程中心。
### 已接入的平台
<div class="link-box">
<a href="https://www.bytecho.net" class="no-underline" title="字节星球" target="_blank" >
<div class="content"><p class="title">字节星球</p></div>
</a>
<a href="https://moshanghua.net" class="no-underline" title="陌上花" target="_blank" >
<div class="content"><p class="title">陌上花</p></div>
</a>
</div>
---
Henry 2023-09-06
微分方程小手册https://www.bytecho.net/archives/2307.html2023-09-06T08:20:00.000Z### 微分方程框架
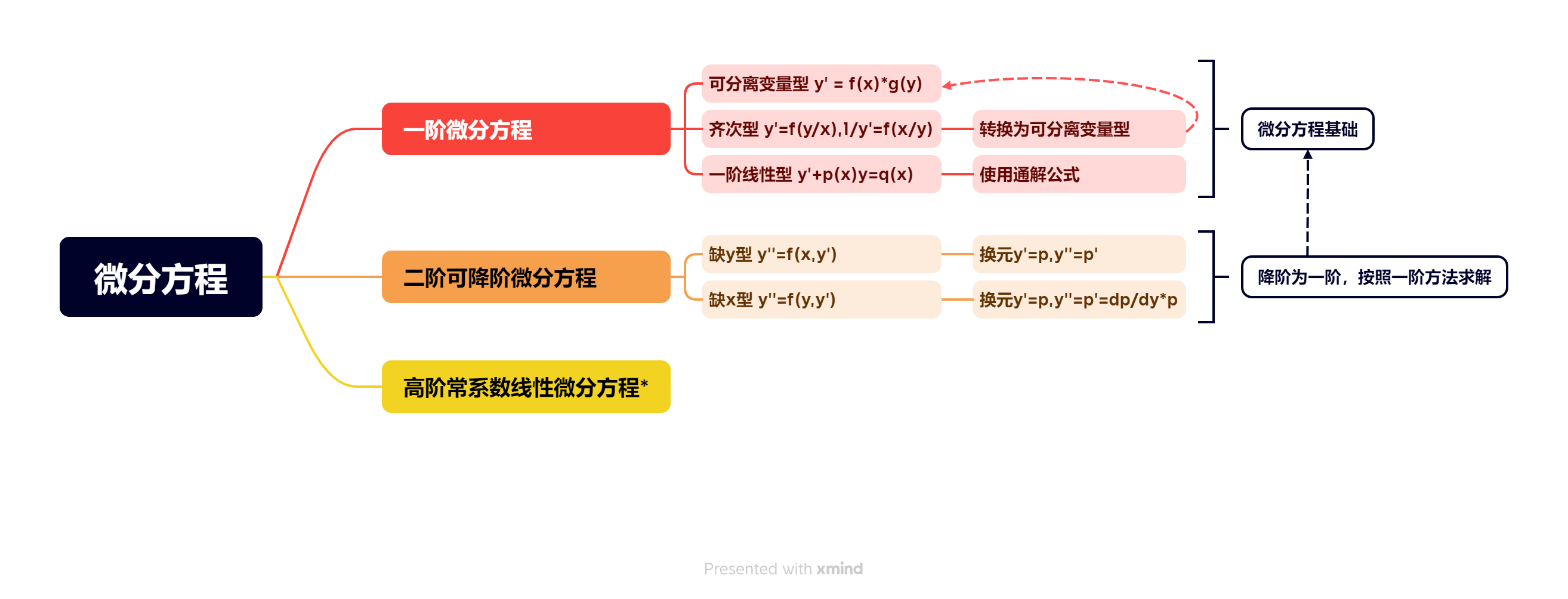
### 一阶微分方程
#### 可分离变量型
形如:${\rm{y}}' = f(x) \cdot g(y)$,有:
$$
{\rm{y}}' = f(x) \cdot g(y) \Rightarrow \frac{{dy}}{{dx}} = f(x) \cdot g(y) \Rightarrow f(x) \Rightarrow \frac{{dy}}{{g(y)}} = f(x)dx \Rightarrow \int {\frac{{dy}}{{g(y)}}} = \int {f(x)dx}
$$
进一步的,可通过换元得到以上形式的,也可以对其分离变量,如:
$$
{\rm{y}}' = f(ax + by + c) \Rightarrow u{\rm{ = }}ax + by + c \Rightarrow \frac{{dy}}{{dx}} = f(u) \Rightarrow \frac{{du}}{{dx}} = a + bf(u) \Rightarrow \frac{{du}}{{a + bf(u)}} = dx \Rightarrow \int {\frac{{du}}{{a + bf(u)}}} = \int {dx}
$$
#### 齐次型
形如$y'=f(\frac{y}{x})$或$\frac{1}{y'}=f(\frac{x}{y})$,按照上述方法换元转换为分离变量型,以$y'=f(\frac{y}{x})$为例,令$u=\frac{y}{x}$,有:
$$
y = ux \Rightarrow \frac{{dy}}{{dx}} = x\frac{{du}}{{dx}} + u \Rightarrow y' = \frac{{dy}}{{dx}} = f(u) = x\frac{{du}}{{dx}} + u \Rightarrow \int {\frac{1}{{f(u) - u}}du = \int {\frac{{dx}}{x}} }
$$
#### 一阶线性型
形如:$y'+p(x)y=q(x)$,使用以下公式计算(由于是应试,推导步骤略):
$$
y = {e^{ - \int p (x)dx}}\left[ {{{\int e }^{\int p (x)dx}} \cdot q(x)dx + C} \right]
$$
上式为一阶线性微分方程的通解公式,其中,式中的${\int p (x)dx}$为$p(x)$的某一个原函数。
注:上述公式中若$\int p (x)dx = \ln \left| {\varphi (y)} \right|$,该绝对值在上述公式中最后可以去掉,产生的$±$可以合并到常数$C$中得到常数$D$。
### 二阶微分方程(可降阶)
**形如:$y''=f(x,y')$,即缺$y$型,令$y'=p,y''=p'$,有:**
$$
y'' = \frac{{dp}}{{dx}} = f(x,y') = f(x,p)
$$
由上式降阶为一阶微分方程,按一阶微分方程方法求解得到$p=y'=\varphi(x,C_1)$,则可求得原微分方程通解:
$$
y=\int \varphi(x,C_1)dx+C_2
$$
**形如:$y''=f(y,y')$,即缺$x$型,令$y'=p,y''=p'=\frac{dp}{dx}=\frac{dp}{dy} \cdot \frac{dy}{dx}=\frac{dp}{dy} \cdot p$,有:**
$$
y''=\frac{dp}{dy} \cdot p=f(y,p)
$$
由上式降阶为一阶微分方程,按一阶微分方程方法求解得到$p=y'=\varphi(y,C_1)$,分离变量后积分即可求得原微分方程的通解:
$$
\frac{{dy}}{{\varphi (y,{C_1})}} = dx \Rightarrow \int {\frac{{dy}}{{\varphi (y,{C_1})}}} = \int {dx} = x + {C_2}
$$
### 高阶常系数线性微分方程*
**对于形式为:$y''+py'+qy=f(x)$,$y''+py'+qy=f_1(x)+f_2(x)$求解步骤如下:**
1. 写出方程$\lambda^2+p\lambda+q=0$,解出$\lambda_1,\lambda_2$或共轭复根;
2. 根据以下类型,写出齐次线性微分方程的**通解**:
$$
y = \left\{ {\begin{array}{*{20}{l}}
{{C_1}{e^{{\lambda _1}x}} + {C_2}{e^{{\lambda _2}x}},}&{{p^2} - 4q > 0(root:{\lambda _1} \ne {\lambda _2})}\\
{({C_1} + {C_2}x){e^{\lambda x}},}&{{p^2} - 4q = 0(root:{\lambda _1} = {\lambda _2} = \lambda )}\\
{{e^{\alpha x}}({C_1}\cos \beta x + {C_2}\sin \beta x),}&{{p^2} - 4q < 0(root:\alpha \pm \beta i)}
\end{array}} \right.
$$
3. 对于第一种形式,直接根据自由项$f(x)$的形式设**特解**,对于第二种形式需分别根据自由项$f_1(x),f_2(x)$的形式设两个特解,然后相加得到微分方程的特解,特解形式如下:
$$
y^* = \left\{ {\begin{array}{*{20}{l}}
{{e^{\alpha x}}{Q_n}(x){x^k},}&{f(x) = {P_n}(x){e^{\alpha x}}}\\
{{e^{\alpha x}}\left[ {Q_l^{(1)}(x)\cos \beta x + Q_l^{(2)}(x)\sin \beta x} \right]{x^k},}&{f(x) = {e^{\alpha x}}\left[ {{P_m}(x)\cos \beta x + {P_n}(x)\sin \beta x} \right]}
\end{array}} \right.
$$
上式中的$e^{\alpha x}$直接从自由项中照抄,$Q_n$为$x$的$n$次一般多项式,$l=max\{m,n\}$,$Q_l^{(1)},Q_l^{(2)}$分别为$x$的两个不同的$l$次一般多项式。
$k$在${p^2} - 4q \ge 0$时:$\alpha$与所有特征根都不相等,此时$k=0$;与其中一个特征根相等,$k=1$;与所有特征根相等,$k=2$。
$k$在${p^2} - 4q < 0$时:$\alpha \pm \beta i$不是特征根,此时$k=0$;$\alpha \pm \beta i$是特征根,$k=1$。
最后,将**齐次微分方程的通解加上该微分方程的一个特解**即是非齐次微分方程的通解,简单来说就是先写齐次通解再设非齐次特解,相加得非齐次通解。
**对于$y^{(n)}(n \ge 3)$的情形:**
形如$y'''+p_1y''+p_2y'+p_3y=0$,同样的写出特征方程:$\lambda ^3+p_1\lambda^2+p_2\lambda+p_3=0$,解得$\lambda_{1,2,3}$,然后根据以下不同情况直接写出通解:
1. 若$\lambda_i$为单实根:$Ce^{\lambda x}$;
2. 若$\lambda_i$为$k$重实根:$(C_1+C_2x+C_3x^2+\cdots+C_kx^{k-1})e^{\lambda x}$;
3. 若$\lambda_i$为单复根$\alpha\pm\beta i$:$e^{\alpha x}(C_1cos\beta x+C_2sin\beta x)$。
将上述每一个特征根产生的项相加,得到$y$的齐次通解。
### 下载PDF
[file href="/api/v1/uploads/file/00edd082e9ab70c399707fe1b955de9354ed695d.pdf"]微分方程.pdf[/file]
---
Henry 2023-09-06
近期小记https://www.bytecho.net/archives/2281.html2023-07-22T10:18:00.000Z> 炎热的夏天,只能天天在家,没有一点能令人精神的清新而凉爽的空气,搞的一天昏昏沉沉!
家里台式已然是个老不死,还剩最后一口气只能说,死缠烂打之下家里台式机换了新的平台+AMD R7某系列CPU(顺便提一嘴,全能本夏天真难用,散热简直是灾难,不然我也没什么用台式的需求),然而之前的航嘉电源好像有些不稳定,寄去上海修了,也不知道上海那个 B 修电源的啥时候才能给你弄好,寄回来还得三四天,真的难受。
今天帮人搭建 OJ 系统,人家给了 100 左右,还白嫖到了高质量题库,满意!(哦不对,应该是昨天,已经过了12点了~
续上:又有信奥培训机构的判题后端服务遇到了疑难杂症,redis的docker容器反复重启...帮忙解决了,人家主动给了些辛苦费。
今天又发现上次给人搭建的评测机的安全沙箱跑不起来,排查了一下发现是CentOS7导致的问题,配置了一下解决。
此外不得不说,使用docker部署各类业务,使得自己的服务器干净了不少,对有电子洁癖的我非常友好,现在已经对自己的服务器爱不释手了,而不是跟之前一样嫌弃得都不想打开。
现阶段一天天盼望着能够工作,十多年的应试生活,早就已经厌倦了,你说真能学到什么?也就是培养了学习能力和拿到了找工作的敲门砖,实践还得自己来。目前我的好多想法都只能有稳定收入和足够的时间之后才敢尝试,期待这一天!
字节星球(肥柴之家)搬家了!https://www.bytecho.net/archives/2274.html2023-06-03T12:19:00.000Z### 新闻
字节星球/肥柴之家业务现已迁移至新服务器,告别 106.54.176.177,**全面使用 Docker 部署~**
本次迁移的业务:主站、Blog(暂未使用,仅作为测试)二级、Api二级、Code(Flarum)二级。
~~注:以上服务有用的准确来说只有一个...~~
新增业务:[OnlineJudge](https://acm.bytecho.net)(信息学在线评测服务)欢迎注册使用、私有Git服务以及[服务探针](https://status.bytecho.net)。
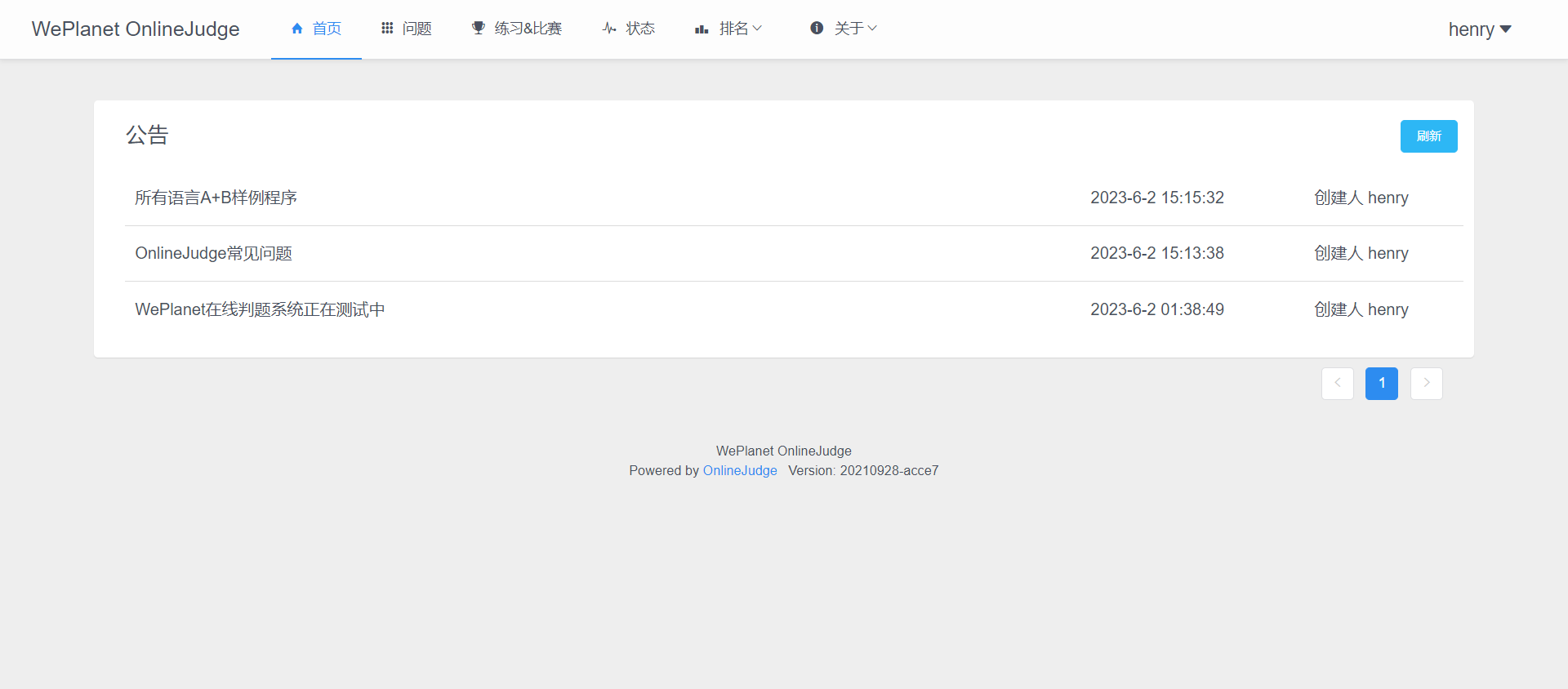
后续会上线WePlanet Web端(Go+ElementUI,桌面端现已上线)、Home二级(用作字节星球生态导航)。
**注意,Images二级域已经废弃,所以大家的友情链接头像地址需要更新,新的头像地址已在[传送门](https://www.bytecho.net/links.html)页面更新。**
### 另外
106.54.176.177(腾讯云CVM)用了三年,也算是基本横跨了大学四年了,新的服务器(腾讯云)又将跨越我的研究生三年,蛮有意思!
注:本人腾讯忠实铁粉。
另外,在线判题服务器又再次开放了,在合适的时机投入使用!
### 新的开始

(附一张❤️李庚希的照片,她饰演的角色几乎都符合我心中的理想型,或许可以作为一种无形动力?)
还有十来天就算是本科正式毕业了,读完大学本科,发现个人似乎还是喜欢中学时的那种同学情谊,但教学模式和生活方式我还是更喜欢大学一点。
不管是喜欢与否,这些都已经成为回忆,我发现对于我而言,不论是快乐的还是负面的回忆,都让我觉得美好,始终还是一个喜欢念旧的人,以前的东西舍不得扔,以前的事情也舍不得忘。
继续自己的学术道路(可能是刚刚开始,毕竟本科算不上什么学术)吧,开启硕士研究生生活,本人现在最大的梦想还是能够留在重邮工作!
---
Henry 2023-06-03
如何顺利注册ChatGPT?https://www.bytecho.net/archives/2257.html2023-04-24T07:53:00.000Z### ChatGPT
欢迎来到 ChatGPT,这里是一个 AI 智能助手,可以帮助您解答各种问题。其实这已经火了一段时间了,现在也推出了付费的ChatGPT Plus **USD $20/m**。
俗话说,**但凡和网红沾边的东西,都多少沾点**,GPT也不例外...因为注册用户太多,以及接口的滥用,现在已经封IP、封邮箱、封账号了,我在今天(2023-04-24)才选择注册ChatGPT,一直因为它是网红而不想去凑热闹。
### 开始注册
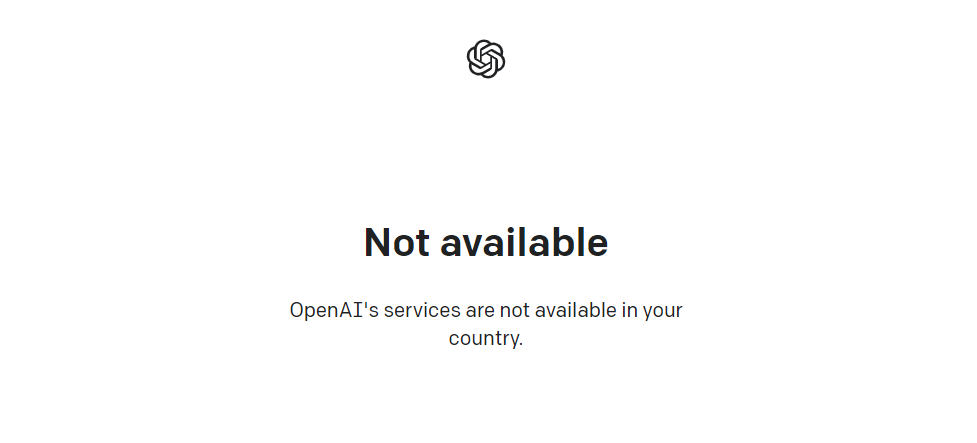
请自备一些地区的网络,其中`CN_MAINLAND,CN_HK,CN_TW`除外!
不然你第一步就阵亡了:
#### 访问官网
其网址为:https://chat.openai.com/
#### 关于邮箱
我这边给你们指一条明路(坑已经被我踩过了):注册时,不要用什么QQ邮箱等烂大街的国内邮箱,大部分人为了方便都会选择这些邮箱,也不要用什么自己的域名邮箱(如bytecho.net邮箱),这些通通会在手机验证码步骤时出现如下错误:
`Your account was flagged for potential abuse. If you feel this is an error, please contact us at help.openai.com.`
**请直接用Google账号注册**,别用花里胡哨的邮箱去注册。
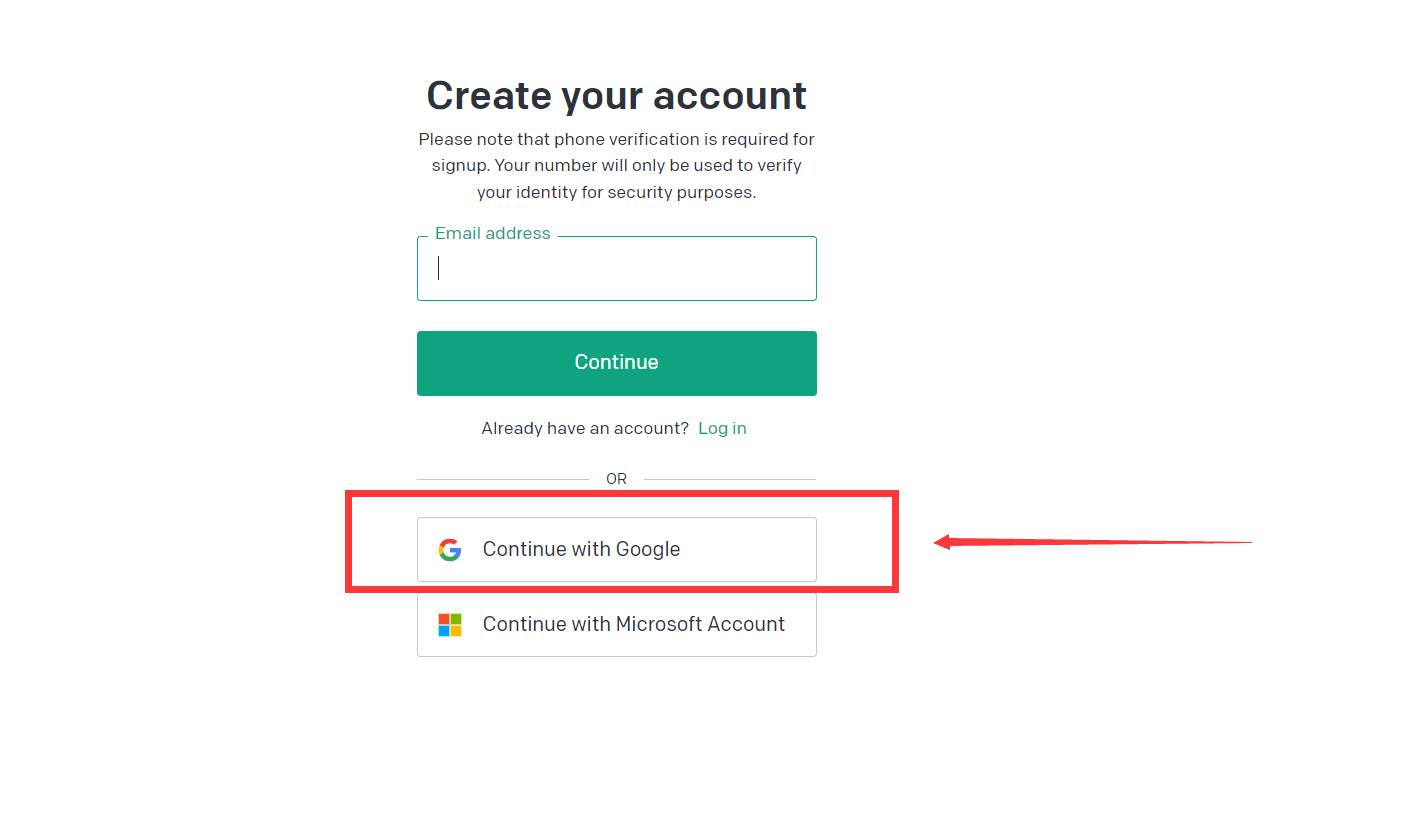
并且这样还不需要接收邮件验证码,直接进入下一步。
#### 填写个人信息
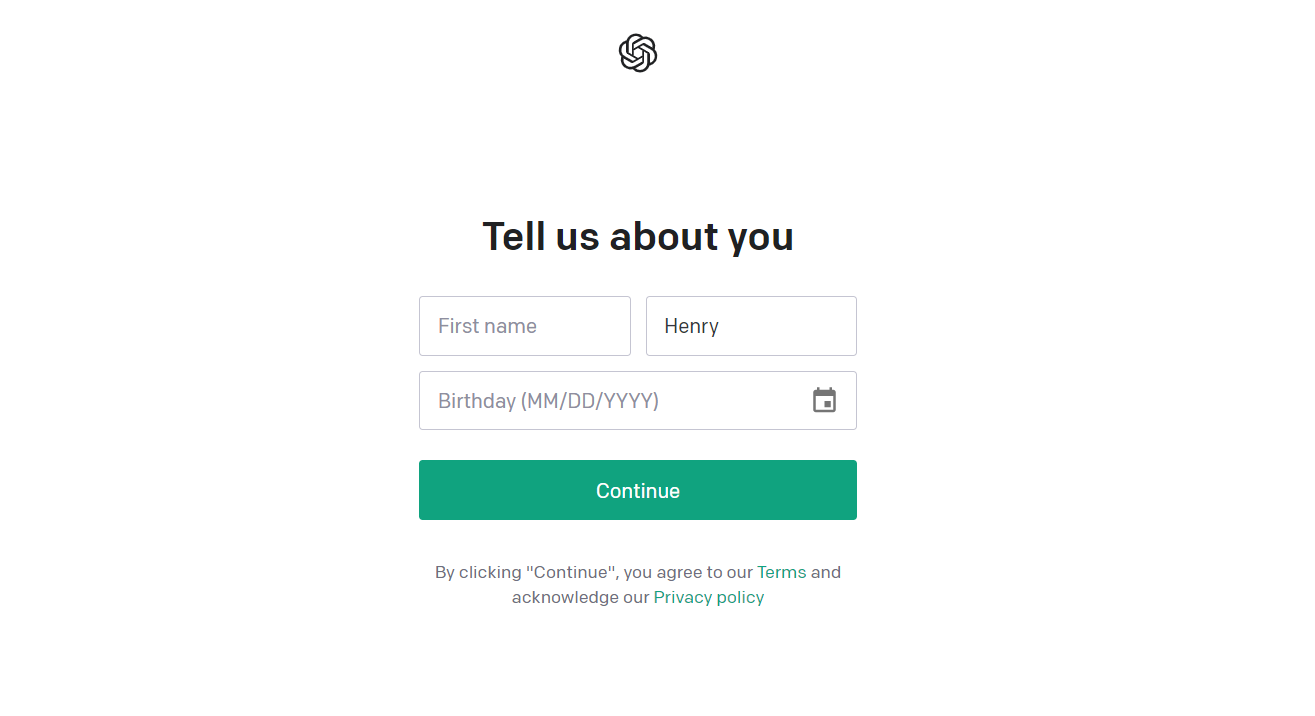
这一步暂时无坑。
#### 手机号验证
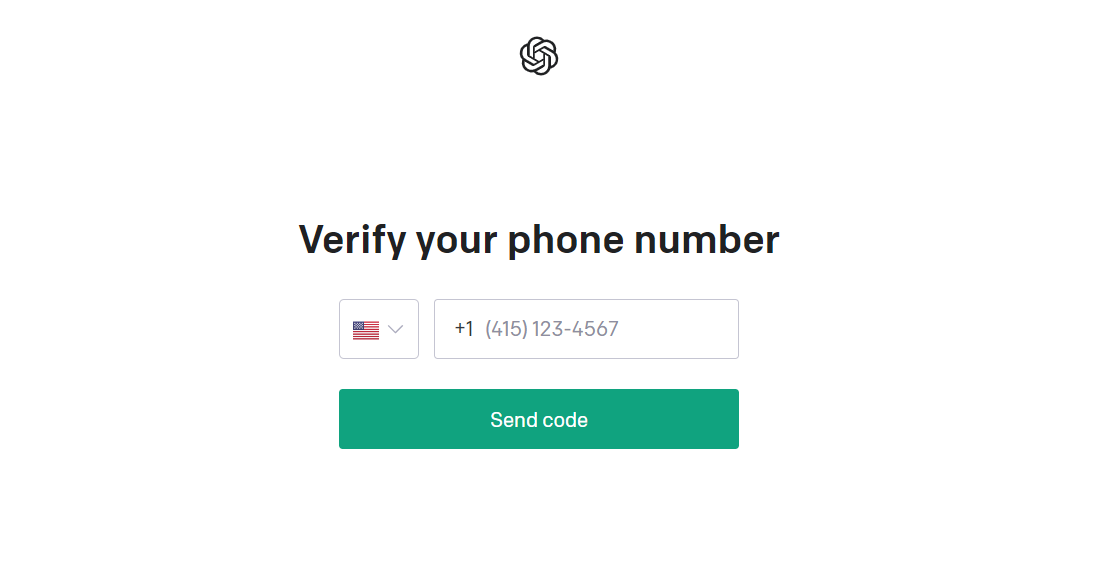
首先国内手机号不用想了,用不了,只能用一些虚拟手机号平台,如:https://sms-activate.org/
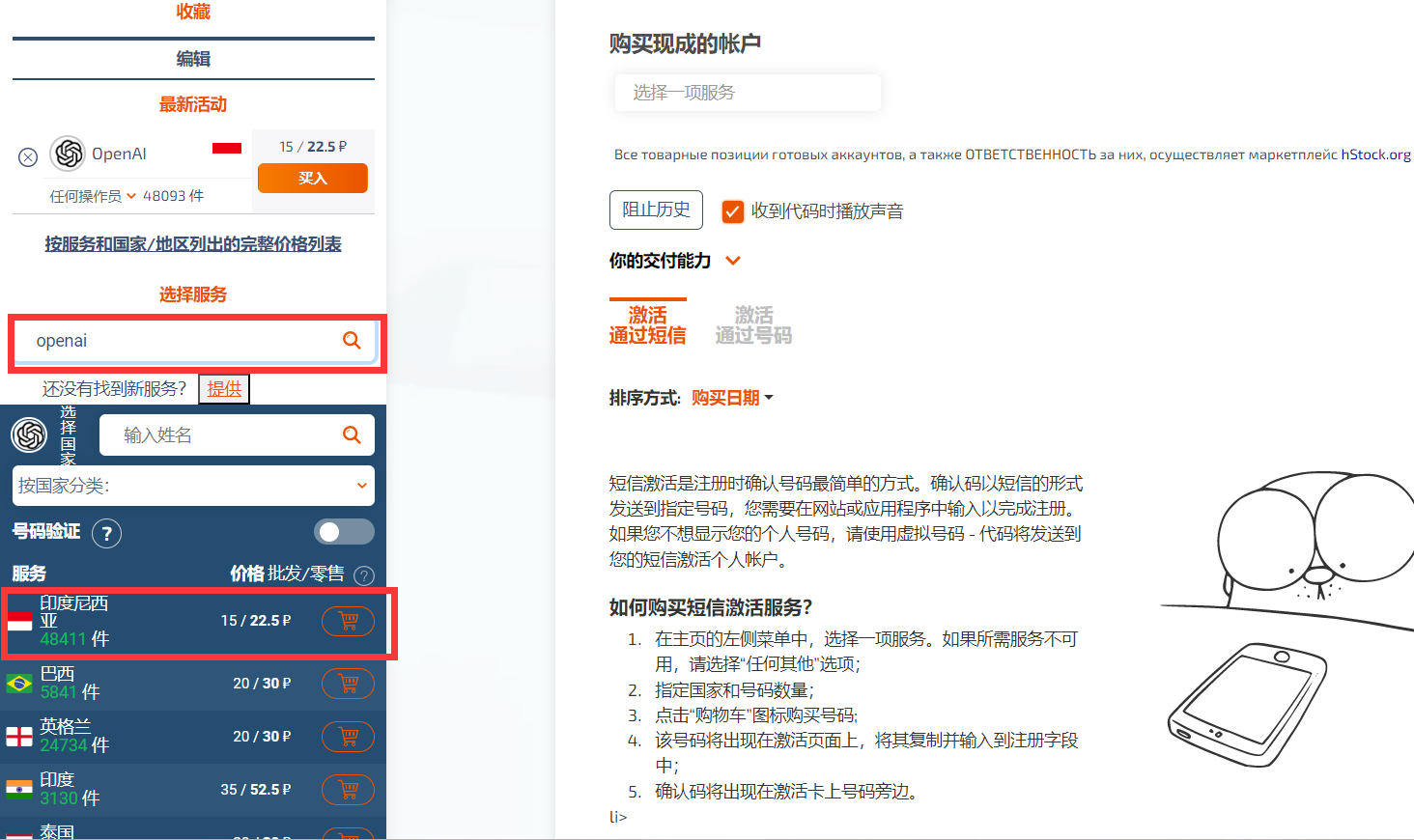
直接选择OpenAI,选择印度尼西亚的手机号(目前还没有出现滥用问题),如果出现`Your account was flagged for potential abuse.`点×取消订单就行,然后再次下单会有新的手机号产生,反复尝试。
**注:如果邮箱有问题,不管你用什么手机号都会出现`Your account was flagged for potential abuse.`**
#### Over
### 功能演示
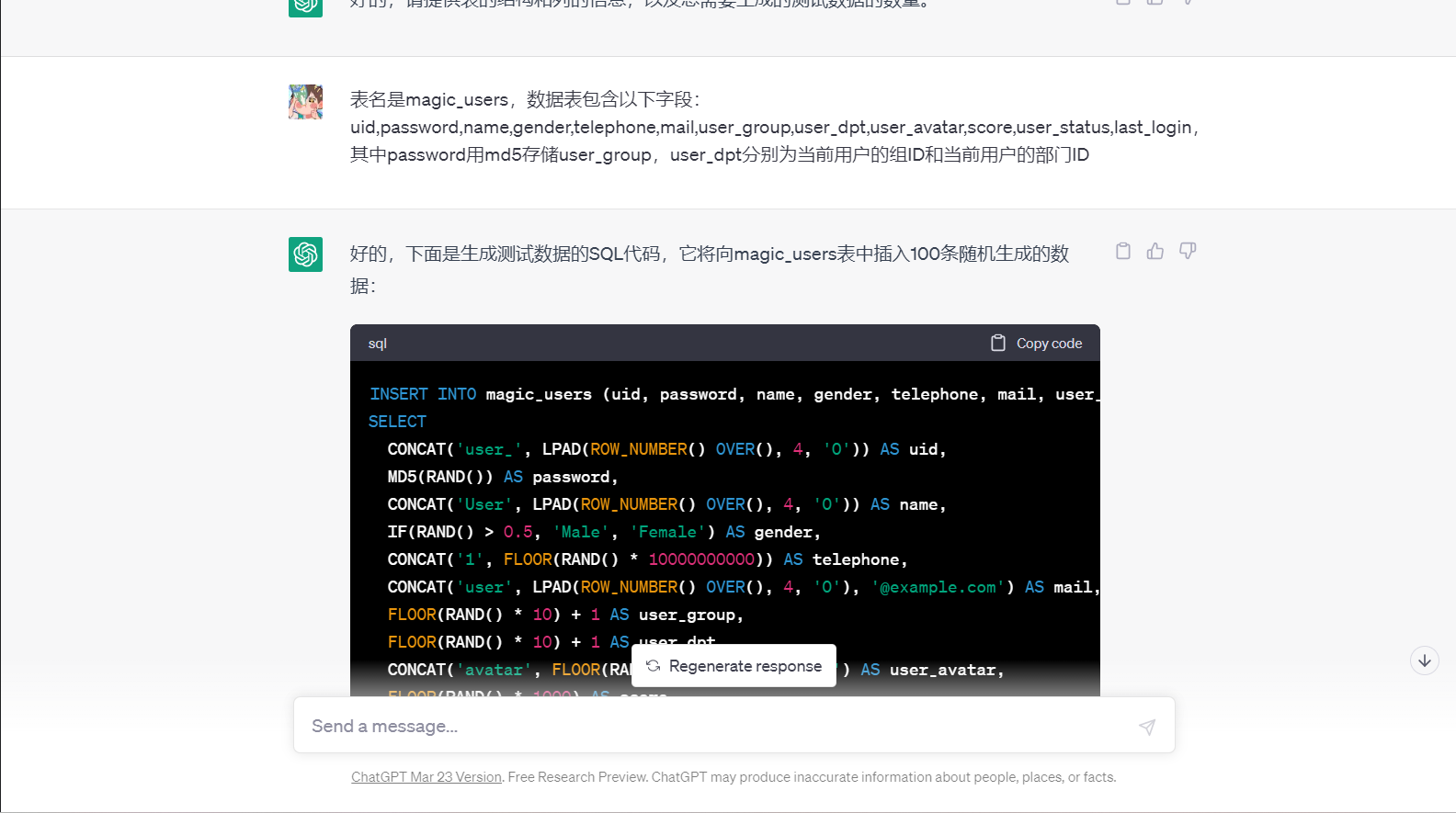
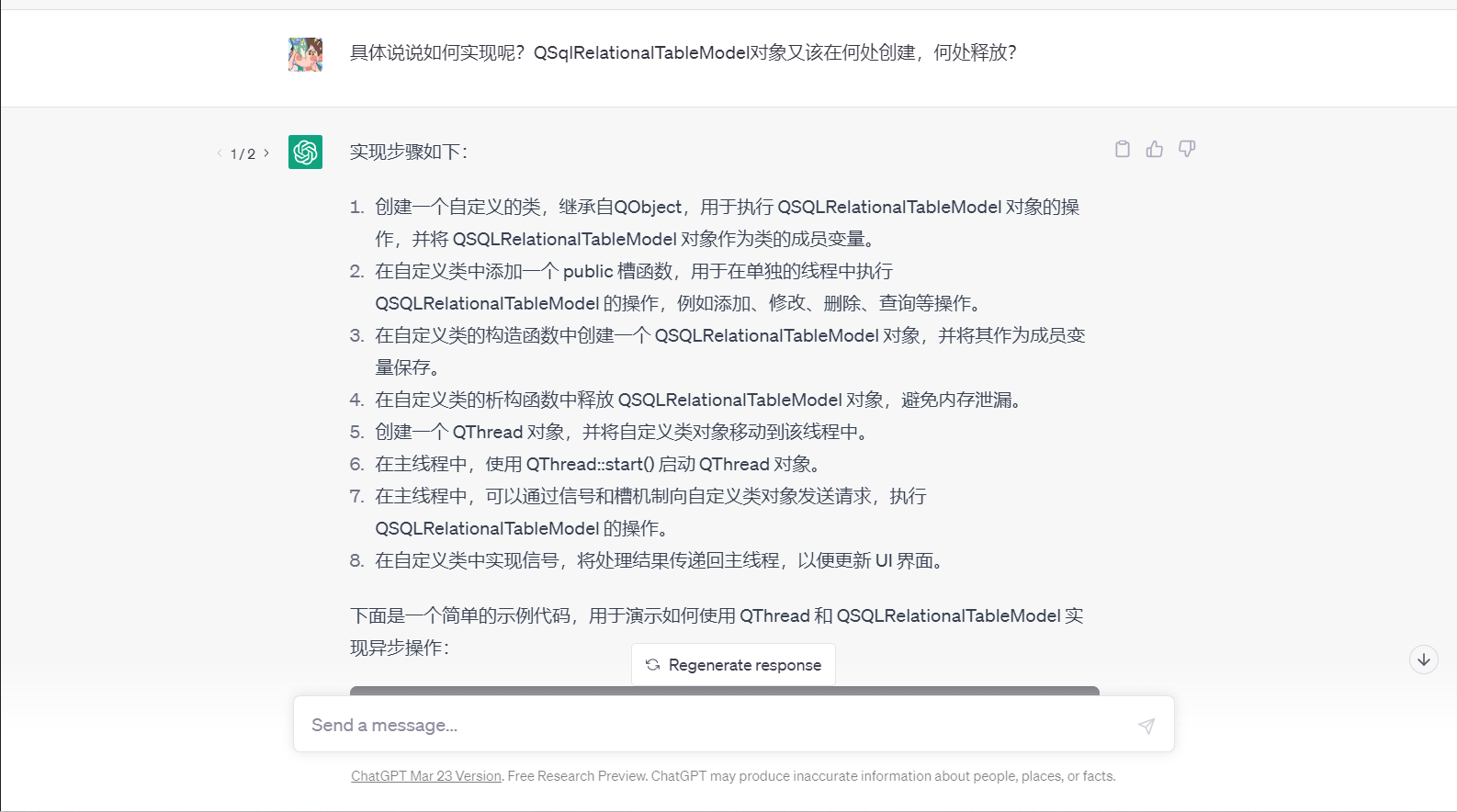
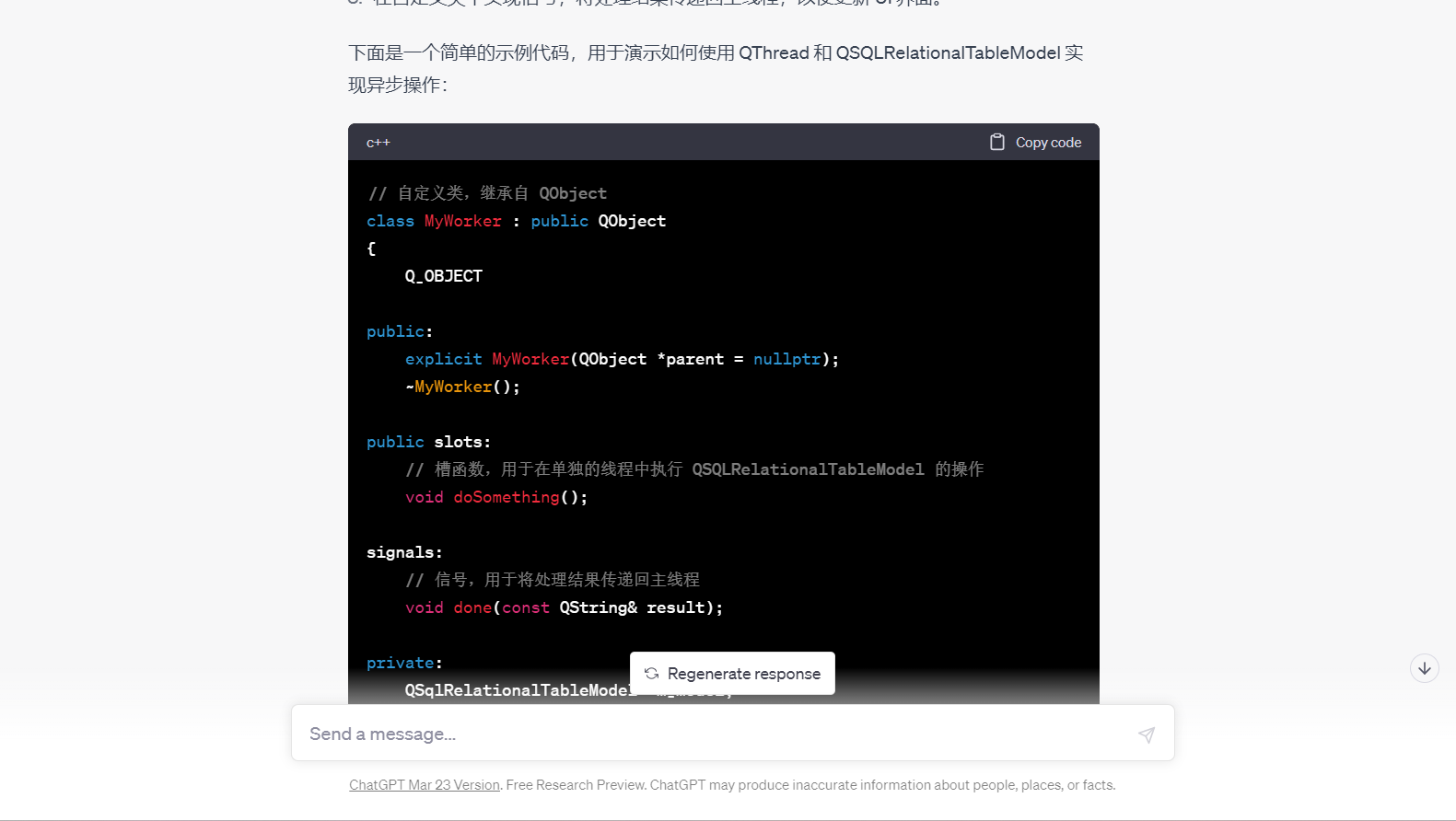
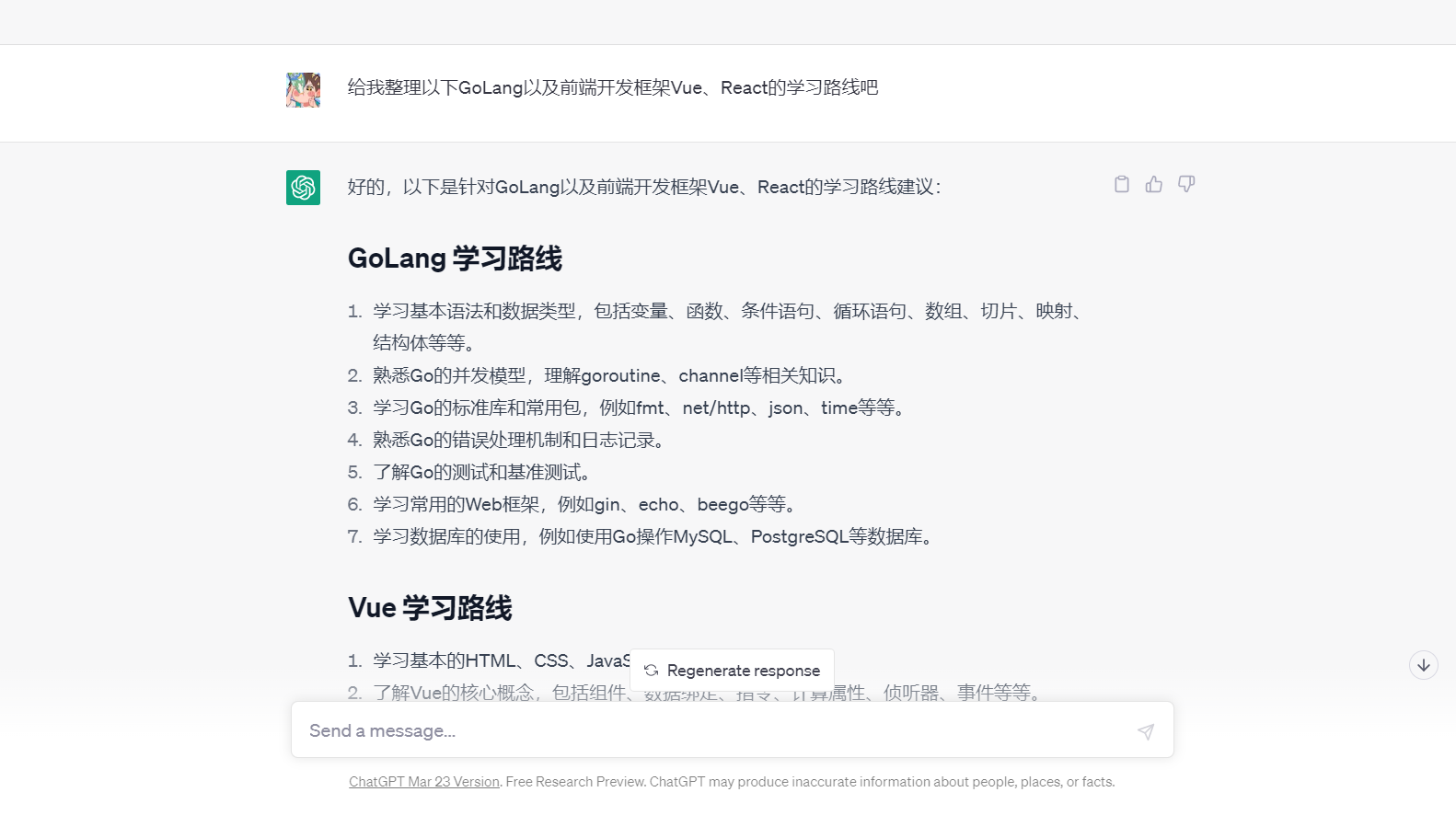
---
字节星球 Henry 2023-04-24 **未经许可 严禁转载!**
https://www.bytecho.net/archives/2257.html
披着CLion的外衣实则在讲CMakehttps://www.bytecho.net/archives/2225.html2023-01-29T04:08:00.000Z### CLion 配置
#### 安装和基础设置
至于 CLion 安装和基础设置,网上教程一大把,而且不是学习重点,根据自己需求配置即可。
#### 工具链配置
这个配置是进行 C++ 开发的关键,因为这个编译工具链就意味着 C++ 的编译环境。
按下图点开对应的信息,如果你任何编译工具链都没有添加,由于新版本的 CLion 它会自带一个 mingw 的编译套件,所以默认会有一个 CLion 自带的 mingw 编译工具链。
如下图所示我的编译工具链稍微有点丰富,有 msvc、g++、clang++、mingw,作为一个刚刚入门学编程的新手,我建议编译工具链这一块暂时就没必要了解了,但在 CLion 中编译的具体配置流程我认为还是有必要讲清楚。
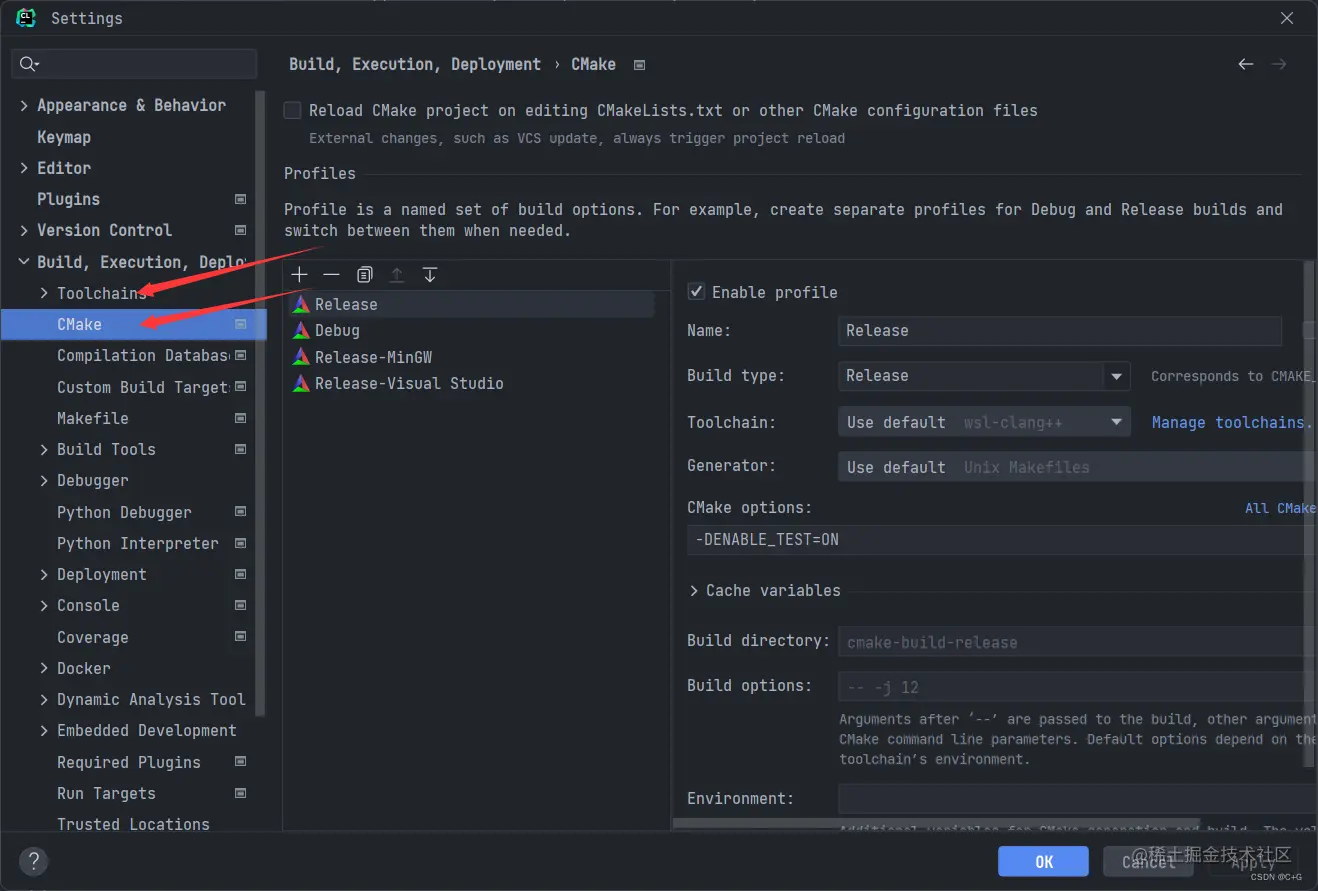
CLion 中添加编译工具链非常简单,你本机把对应工具链的路径加入到了环境变量,那么在你点击 `+` 对应编译链类型后,会自动扫描到,如果实在没有扫描到,那么也可以自己填入对应的路径,整个编译链包括:
1. cmake,用于跨平台以及简化底层编译脚本的工具。
2. cmake 生成更底层的编译命令(对应上述的 Build Tool),比如 gmake 也就是解析.makefile 文件进行命令执行,比如 ninja 解析 .ninja 文件进行命令执行(编译速度比 makefile 更快)。
3. C 语言的编译器(clang/gcc/cl 等等)。
4. C++ 的编译器(clang++/g++/cl 等等)。
如果是 mingw,那么上述的一套都是包含的,只需要把 Toolset 这个选项选择为 mingw 对应的目录即可,选择好后,CLion 会自动识别上述四件套的位置。
接下来简单介绍如何添加一些工具链:
* 安装 msvc 编译工具链:直接到官网下载 VS2022,然后安装对应 C++ 环境,打开 CLion 后添加 msvc 环境时就会自动识别。官网:https://visualstudio.microsoft.com/zh-hans/vs/
* 安装 wsl2:其实 wsl2 的安装已经被简化到了极致,在 powershell 中 `wsl --install` 即可。
具体的官方文档如下:https://learn.microsoft.com/zh-cn/windows/wsl/install
* 如果需要使用 CLion 进行 Qt 开发,可以查看视频讲解:[www.bilibili.com/video/BV18q…](https://link.juejin.cn?target=https%3A%2F%2Fwww.bilibili.com%2Fvideo%2FBV18q4y1i7kV%2F "https://www.bilibili.com/video/BV18q4y1i7kV/") ,对应的配置信息:[gitee.com/yuexingqin/…](https://link.juejin.cn?target=https%3A%2F%2Fgitee.com%2Fyuexingqin%2Ftemplate_qtclion "https://gitee.com/yuexingqin/template_qtclion")
* 如果需要使用 CLion 进行 STM32 开发,那么可以查看稚晖君在知乎写的博客教程:[zhuanlan.zhihu.com/p/145801160](https://link.juejin.cn?target=https%3A%2F%2Fzhuanlan.zhihu.com%2Fp%2F145801160 "https://zhuanlan.zhihu.com/p/145801160")
### CMake 配置项
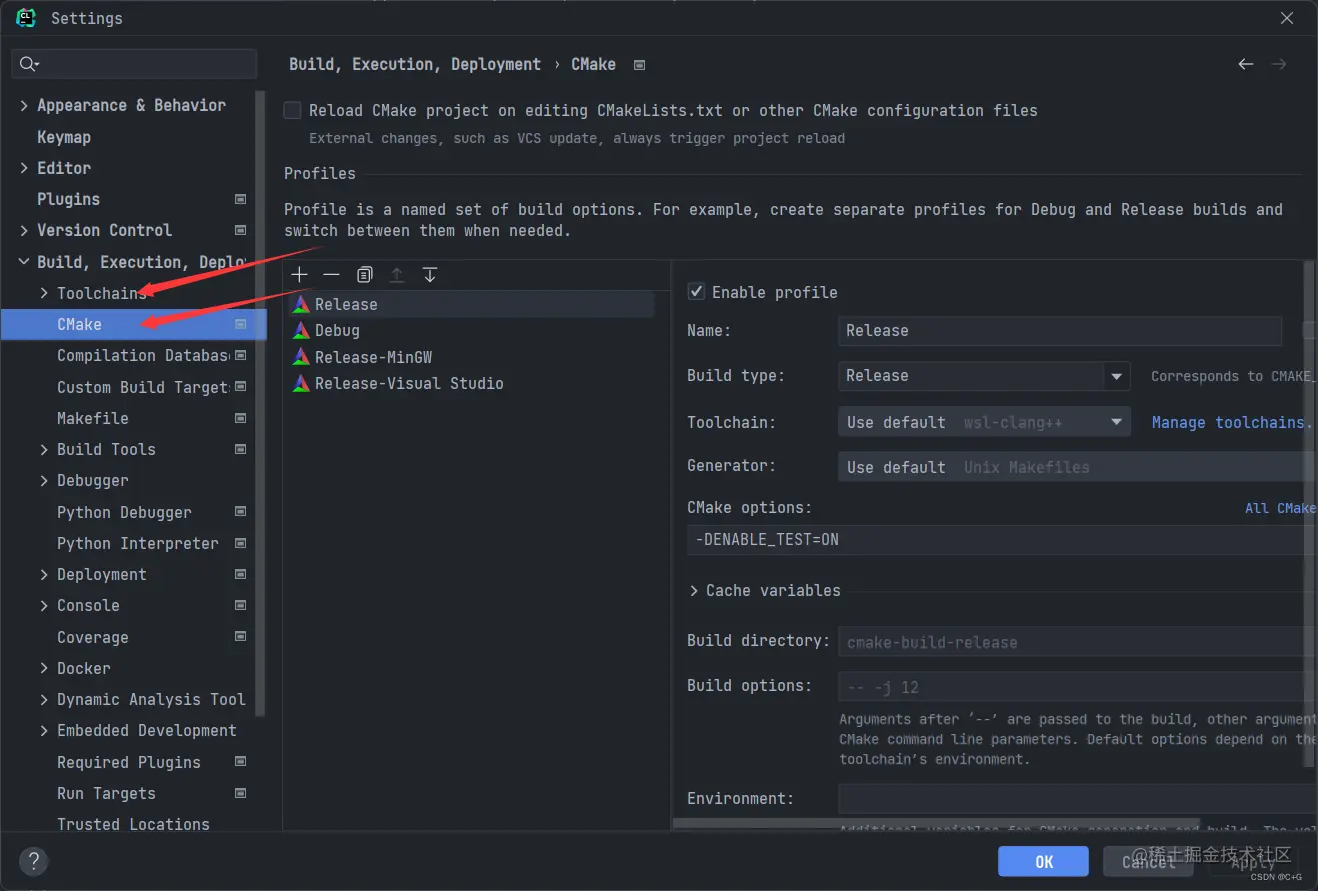
如上图所示,第二个 `CMake` 选项就是我们现在要讲的,而这两个正好也是整个开发环境中最重要的东西,第一个编译工具链决定了 CLion 中已经识别了本机有哪些编译环境,而第二个 `CMake` 选项,则是用于配置 cmake 基于哪些配置项生成。
所以我们现在应该了解了 CLion 是如何去编译项目生成可执行文件的了。
1. 通过 cmake 配置选项运行整个项目的 CMakeList.txt
2. 生成 makefile 或其他底层脚本后再通过对应的工具去执行这个脚本
3. 运行编译好的程序
而我们现在讲的就是添加 cmake 配置选项,如果你手动写 cmake 命令的话,那样对应的就是命令行参数了。
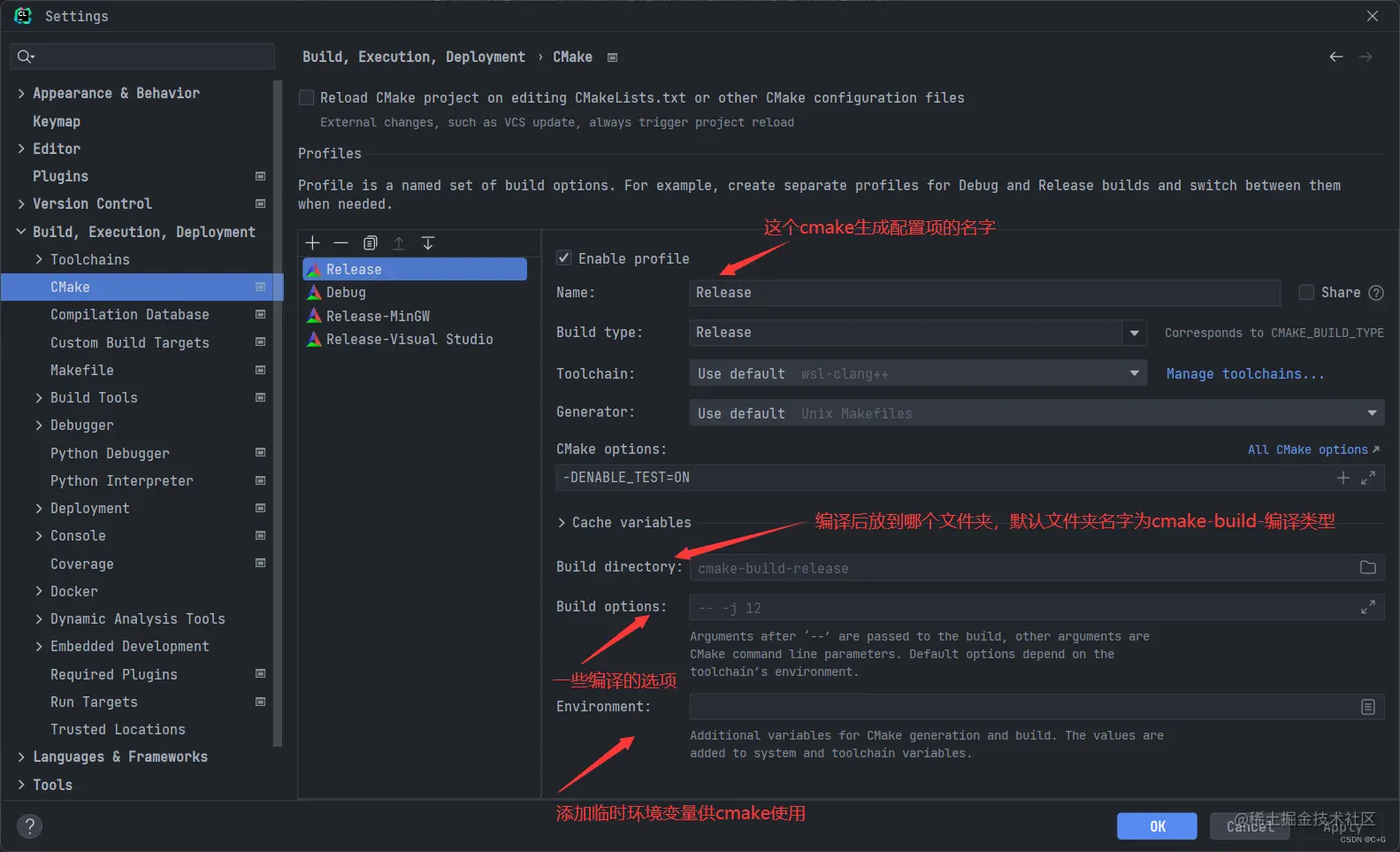
上述图片中已经解释了一些配置的作用。这些配置项一般是不常改动,使用默认值就行,比如 `Build options` 是执行最后的脚本所用的参数,默认为 `-j 12`,比如如果是 makefile,那么就是 `make -j12`。
下面是大家可能需要进行一些配置的选项:
1. Build type:这是程序最终编译的类型,意味着编译器该以何种程度对源代码进行优化,比如 Debug 版本一般再 gcc 中对应 o2 的优化,release 版本对应 o3 的优化,两者一般存在 10 倍左右的性能差距。
2. Toolchain:这是前面所说的编译工具链,一般来说,想要切换编译器,你切换这个选项就行了,默认使用 default 工具链。
3. Generator:这是前面所说的工具链中的较为底层的脚本的运行工具,可以是 makefile 或者 ninja,不选的话也是默认工具链里的那个。
4. CMake options:这个是 cmake 运行时可以加入的命令行参数,比如我们可以-D 来定义对应的变量控制对应的 cmake 行为,甚至于前面的 Build type 我们完全可以不写(当然这是 CLion,这个空必须得被填充),然后使用 `-DCMAKE_BUILD_TYPE=Release`,这个变量可以决定最终 cmake 生成的执行脚本是按照 release 的标准去运行的,又比如 `-DBUILD_SHARED_LIBS=ON`,那么最终是会生成动态库而不是静态库,我上图中的 `-DENABLE_TEST=ON` 是内部的 cmake 有定义一个变量默认为 OFF 值,如果为 ON 时会加入测试代码为子项目。
现在 cmake 在 CLion 中的配置项已经讲完了,简单实践一下来体验之前讲的 CLion 到整个运行的流程:
1. 通过 cmake 配置选项运行整个项目的 CMakeList.txt。
2. 生成 makefile 或其他底层脚本后再通过对应的工具去执行这个脚本。 我们先看一眼上一步 cmake 生成的文件(放出了两个不同的配置项产生的脚本,第一个使用的 Generator 为 ninja,第二个使用的为 gmake):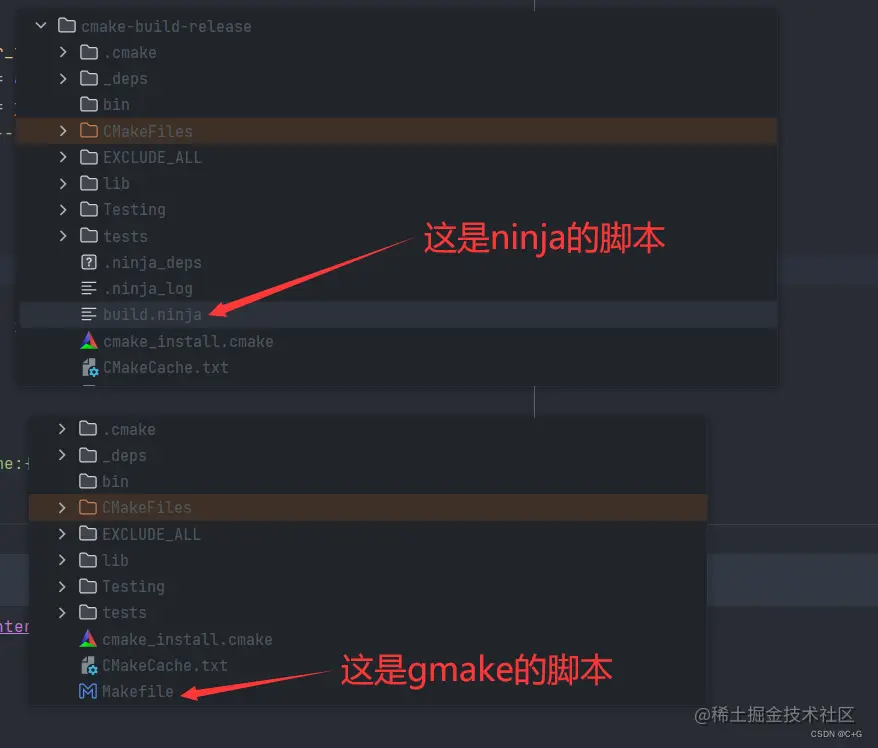
如果想要继续执行这个脚本,应该在 CLion 中执行对应的源代码,CLion 会自动识别入口点函数,然后给出可执行的按钮。点击执行后,不仅会直接对应的 makefile 或 build.ninja 还会顺便把这个程序运行到 CLion 内置的终端环境中。
3. 运行编译好的程序:这一步已经在第二步一并执行了。
#### CMake 的使用与实战
经过上述文字和图片讲解,我们很自然的想到,整个 CLion 运行 C++ 代码其实就是在运行 cmake 和 makefile(或 build.ninja),第二个过程我们参与不了,但是第一个 cmake 的编写过程我们却需要一直接触。
下面用 CLion 新建项目自动生成的 cmake 模板来简单对 cmake 语法热热身。
```cmake
cmake_minimum_required(VERSION 3.22)
project(untitled)
set(CMAKE_CXX_STANDARD 17)
add_executable(untitled main.cpp)
```
* `cmake_minimum_required` 命令:规定了编译本项目的 cmake 工具至少需要 3.22 版本。
* `project` 命令:规定了本项目的项目名称,同时也根据这个传入的值生成了一堆变量,常用的如下:
1. `PROJECT_NAME` :项目名称
2. `PROJECT_BINARY_DIR` :项目的二进制文件目录,即编译后的可执行文件和库文件的输出目录
3. `PROJECT_SOURCE_DIR` :项目的源文件目录,即包含 CMakeLists.txt 文件的目录
举个简单例子说明上述变量的作用:
比如一个测试的子项目中的 CMakeList.txt,可能需要写下面的语句(先不管 file 命令),由于是作为直接的子项目,那么里面肯定不会存在 project 语句,所以 PROJECT_SOURCE_DIR 变量表示的仍然是整个项目的根目录,直接通过 `${}` 的形式来使用它即可,这样就不需要关心相对或绝对路径了。
```cmake
file(GLOB SONIC_TEST_FILES
"${PROJECT_SOURCE_DIR}/tests/*.h"
"${PROJECT_SOURCE_DIR}/tests/*.cpp"
)
```
* `set` 命令:设置对应变量为对应的值,该变量存在,则修改该变量的值,如果不存在则会创建并初始化为对应的值,这里对 set 的使用是设置了 CMAKE_CXX_STANDARD 变量为 17,这个变量可以控制最终编译采用的 C++ 版本,这里是使用 C++17。
* `add_executable` 命令:这是用于生成可执行程序的命令,第一个参数为该执行程序最终编译后生成的文件名,后面跟着的都是需要编译的源代码。
对于新手而言,其实不太需要自己手写 cmake,因为 CLion 会在你新建源文件的时候把相应源文件添加到 add_excutable 命令的后面,但项目稍微大一点或者说引入了很多外部库,那么大概率会抛弃 CLion 的这种自动化了。
#### 常用的 CMake 变量
下面只列出了部分变量的作用,更多的变量请查看文档:https://cmake.org/cmake/help/latest/manual/cmake-variables.7.html
* `PROJECT_NAME` :项目名称
* `PROJECT_BINARY_DIR` :项目的二进制文件目录,即编译后的可执行文件和库文件的输出目录
* `PROJECT_SOURCE_DIR` :项目的源文件目录,即包含 CMakeLists.txt 文件的目录
* `CMAKE_BINARY_DIR` :当前 CMake 运行的二进制文件目录,通常和 PROJECT_BINARY_DIR 是同一个目录
* `CMAKE_SOURCE_DIR` :当前 CMake 运行的源文件目录,通常和 PROJECT_SOURCE_DIR 是同一个目录
* `CMAKE_C_STANDARD` :指定 C 语言的标准版本
* `CMAKE_CXX_STANDARD` :指定 C++ 语言的标准版本
* `CMAKE_CXX_FLAGS` :指定编译 C++ 代码时使用的编译选项
* `CMAKE_C_FLAGS` :指定编译 C 代码时使用的编译选项
* `CMAKE_EXE_LINKER_FLAGS` :指定链接可执行文件时使用的链接选项
* `CMAKE_SYSTEM_NAME` :指定当前操作系统名称(如 Windows、Linux 等)
* `CMAKE_SYSTEM_PROCESSOR` :指定当前处理器的类型(如 x86、x86_64 等)
* `CMAKE_CXX_COMPILER_ID` :指定了当前使用的 C++ 编译器,同理可得 C 的编译器对应的名字。
##### 对这些变量做一个简单的实践
通过 message 打印出 `PROJECT_BINARY_DIR、PROJECT_SOURCE_DIR、CMAKE_BINARY_DIR、CMAKE_SOURCE_DIR` 来加以验证,目录结构如下:
```
.
├── CMakeLists.txt
├── main.cpp
└── sub
└── CMakeLists.txt
```
```cmake
main:
cmake_minimum_required(VERSION 3.14)
project(main)
add_subdirectory(sub)
message(STATUS "main:${PROJECT_NAME}\n pro-src:${PROJECT_SOURCE_DIR}\n pro-bin:${PROJECT_BINARY_DIR}\n cmake-src:${CMAKE_SOURCE_DIR}\n cmake-bin:${CMAKE_BINARY_DIR}")
sub:
project(sub)
message(STATUS "sub:${PROJECT_NAME}\n pro-src:${PROJECT_SOURCE_DIR}\n pro-bin:${PROJECT_BINARY_DIR}\n cmake-src:${CMAKE_SOURCE_DIR}\n cmake-bin:${CMAKE_BINARY_DIR}")
```
打印信息如下:我们发现 CMake 对应的变量没有变化,而 Prject 有了变量,因为我们在 sub 也使用了 project 命令。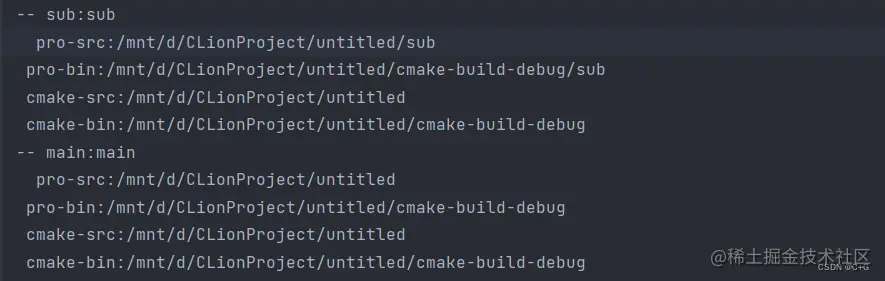
通过变量检测环境执行不同的 cmake 代码:
```cmake
# 判断当前的操作系统
if (CMAKE_SYSTEM_NAME MATCHES "Linux")
target_link_libraries(my-logger PUBLIC fmt-header-only pthread)
message(STATUS "Now is Linux")
elseif (CMAKE_SYSTEM_NAME MATCHES "Windows")
target_link_libraries(my-logger PUBLIC fmt-header-only ws2_32)
message(STATUS "Now is windows")
endif ()
# 判断当前使用的编译器
if (CMAKE_CXX_COMPILER_ID STREQUAL "GNU")
# Do something for GCC
elseif (CMAKE_CXX_COMPILER_ID STREQUAL "Intel")
# Do something for Intel C++
elseif (CMAKE_CXX_COMPILER_ID STREQUAL "Microsoft")
# Do something for Microsoft Visual C++
elseif (CMAKE_CXX_COMPILER_ID STREQUAL "Clang")
`# Do something for Clang`
endif()
# 判断当前的系统架构
if (CMAKE_SYSTEM_PROCESSOR MATCHES "i.86|x86|x86_64|AMD64")
# Do something for x86 architecture
elseif (CMAKE_SYSTEM_PROCESSOR MATCHES "^(arm|aarch64)")
# Do something for ARM architecture
elseif (CMAKE_SYSTEM_PROCESSOR MATCHES "^(mips|mipsel|mips64)")
# Do something for MIPS architecture
elseif (CMAKE_SYSTEM_PROCESSOR MATCHES "^(powerpc|ppc64)")
# Do something for PowerPC architecture
endif()
```
通过调整链接时的 flag 防止动态链接,因为如果你是使用 Windows 平台下的编译工具链,CLion 有些时候最终链接并不是采用静态链接,导致你最终生成的可执行程序没法直接执行,这个时候你就需要使用下面的命令来强制静态链接了:
```
set(CMAKE_EXE_LINKER_FLAGS "-static")
```
#### 常用的 CMake 命令
下列只列出了部分命令,如果你以后有需要用到的其他命令,请前往官网进行查询:[cmake.org/cmake/help/…](https://link.juejin.cn?target=https%3A%2F%2Fcmake.org%2Fcmake%2Fhelp%2Flatest%2Fmanual%2Fcmake-commands.7.html "https://cmake.org/cmake/help/latest/manual/cmake-commands.7.html")
我个人较为常用的命令:
1. [project](https://link.juejin.cn?target=https%3A%2F%2Fcmake.org%2Fcmake%2Fhelp%2Flatest%2Fcommand%2Fproject.html "https://cmake.org/cmake/help/latest/command/project.html"):用于定义项目名称、版本号和语言。
2. [add_executable](https://link.juejin.cn?target=https%3A%2F%2Fcmake.org%2Fcmake%2Fhelp%2Flatest%2Fcommand%2Fadd_executable.html "https://cmake.org/cmake/help/latest/command/add_executable.html"):用于添加可执行文件。第一个参数很重要,被称为 target,可以作为 target_xxx 命令的接收对象。
3. [add_library](https://link.juejin.cn?target=https%3A%2F%2Fcmake.org%2Fcmake%2Fhelp%2Flatest%2Fcommand%2Fadd_library.html "https://cmake.org/cmake/help/latest/command/add_library.html"):用于添加库文件,可以创建静态库或动态库。第一个参数很重要,被称为 target,可以作为 target_xxx 命令的接收对象。简单使用如下
```cmake
add_library(test_lib a.cc b.cc) #默认生成静态库
add_library(test_lib SHARED a.cc b.cc) #默认生成静态库
```
4. [add_definitions](https://link.juejin.cn?target=https%3A%2F%2Fcmake.org%2Fcmake%2Fhelp%2Flatest%2Fcommand%2Fadd_definitions.html "https://cmake.org/cmake/help/latest/command/add_definitions.html"):用于添加宏定义,注意该命令没有执行顺序的问题,只要改项目中用了该命令定义宏,那么所有的源代码都会被定义这个宏 `add_definitions(-DFOO -DBAR ...)` 。
5. [add_subdirectory](https://link.juejin.cn?target=https%3A%2F%2Fcmake.org%2Fcmake%2Fhelp%2Flatest%2Fcommand%2Fadd_subdirectory.html "https://cmake.org/cmake/help/latest/command/add_subdirectory.html"):用于添加子项目目录,如果有该条语句,就先会跑去执行子项目的 cmake 代码,这样会导致一些需要执行后立马生效的语句作用不到,比如 include_directories 和 link_directories 如果执行在这条语句后面,则他们添加的目录在子项目中无法生效。有些命令如 target_include_directories 和 target_link_directories 是根据目标 target 是否被链接使用来生效的,所以这些命令的作用范围与执行顺序无关,且恰好同一个 cmake 项目中产生的库文件是可以直接通过名称链接的,无论链接对象是在子目录还是父目录
6. [target_link_libraries](https://link.juejin.cn?target=https%3A%2F%2Fcmake.org%2Fcmake%2Fhelp%2Flatest%2Fcommand%2Ftarget_link_libraries.html "https://cmake.org/cmake/help/latest/command/target_link_libraries.html"):用于将可执行文件或库文件链接到库文件或可执行文件。身为 target_xxx 的一员,很明显第二个参数也可以进行权限控制。
7. [include_directories](https://link.juejin.cn?target=https%3A%2F%2Fcmake.org%2Fcmake%2Fhelp%2Flatest%2Fcommand%2Finclude_directories.html "https://cmake.org/cmake/help/latest/command/include_directories.html"):用于指定头文件搜索路径,优点是简单直接,缺点是无法进行权限控制,一旦被执行后,后续的所有代码都能搜索到对应的文件路径。
8. [target_include_directories](https://link.juejin.cn?target=https%3A%2F%2Fcmake.org%2Fcmake%2Fhelp%2Flatest%2Fcommand%2Ftarget_include_directories.html "https://cmake.org/cmake/help/latest/command/target_include_directories.html"):指定头文件搜索路径,并将搜索路径关联到一个 target 上,这里的 target 一般是指生成可执行程序命令里的 target 或者生成库文件的 target,与上一个命令的不同点在于可以设置导出权限,比如现在我写了一个项目,这个项目引入了其他库,但是我不想让其他库的符号暴露出去(毕竟使用这个项目的人只关注这个项目的接口,不需要关注其他依赖的接口)可以通过 PRIVATE 将头文件搜索目录设置不导出的权限。
9. [link_directories](https://link.juejin.cn?target=https%3A%2F%2Fcmake.org%2Fcmake%2Fhelp%2Flatest%2Fcommand%2Flink_directories.html "https://cmake.org/cmake/help/latest/command/link_directories.html"):与前面的 include_directories 命令类似,添加的是库的搜索路径。
10. [target_link_directories](https://link.juejin.cn?target=https%3A%2F%2Fcmake.org%2Fcmake%2Fhelp%2Flatest%2Fcommand%2Ftarget_link_directories.html "https://cmake.org/cmake/help/latest/command/target_link_directories.html"):和前面的 include 版本一样的,只是改成了库路径。
11. if\elseif\endif ,在编程语言立马已经用烂了,现在主要是了解 if(condition) 中的条件到底如何判断的,以及内部都支持哪些操作,比如大于等于啥的,这方面直接看官方文档吧,非常好懂:[cmake.org/cmake/help/…](https://link.juejin.cn?target=https%3A%2F%2Fcmake.org%2Fcmake%2Fhelp%2Flatest%2Fcommand%2Fif.html "https://cmake.org/cmake/help/latest/command/if.html")
12. [aux_source_directory](https://link.juejin.cn?target=https%3A%2F%2Fcmake.org%2Fcmake%2Fhelp%2Flatest%2Fcommand%2Faux_source_directory.html "https://cmake.org/cmake/help/latest/command/aux_source_directory.html"):这个指令简单实用,第一个参数传递一个文件目录,它会扫描这里面所有的源文件放到第二个参数定义的变量名中。注意第一个参数只能是文件夹。`aux_source_directory(${PROJECT_SOURCE_DIR} SRC)`
13. [file](https://link.juejin.cn?target=https%3A%2F%2Fcmake.org%2Fcmake%2Fhelp%2Flatest%2Fcommand%2Ffile.html "https://cmake.org/cmake/help/latest/command/file.html"):可以说是上面那个命令的增强版本,但如果熟悉这个命令的朋友肯定很快站出来反对,因为这个命令实在是太强大了,你如果翻一翻这个官方文档就会发现它具备几乎文件系统的所有功能,什么读写文件啊,什么从网上下载文件,本地上传文件之类的它都有,计算文件的相对路径,路径转化等等。但我们平时用到的最多的命令还是用来获取文件到变量里。比如 file(GLOB FILES "文件路径表示 1" "文件路径表示 2" ...) GLOB 会产生一个由所有匹配 globbing 表达式的文件组成的列表,并将其保存到第二个参数定义的变量中。Globbing 表达式与正则表达式类似,但更简单,比如如果要实现前一个命令的功能可以这么写:`file(GLOB SRC "${PROJECT_SOURCE_DIR}/*.cc")`,如果 GLOB 换成 GLOB_RECURSE ,那么上述命令将递归的搜寻其子目录的所有符合条件的文件,而不仅仅是一个层级。
14. [execute_process](https://link.juejin.cn?target=https%3A%2F%2Fcmake.org%2Fcmake%2Fhelp%2Flatest%2Fcommand%2Fexecute_process.html "https://cmake.org/cmake/help/latest/command/execute_process.html"):用于执行外部的命令,如下的示例代码是执行 git clone 命令,执行命令的工作目录在 `${CMAKE_BINARY_DIR}/deps/`:
```cmake
execute_process(COMMAND git clone https://github.com/<username>/<repository>.git
WORKING_DIRECTORY ${CMAKE_BINARY_DIR}/deps/<repository>)
```
15. [message](https://link.juejin.cn?target=https%3A%2F%2Fcmake.org%2Fcmake%2Fhelp%2Flatest%2Fcommand%2Fmessage.html "https://cmake.org/cmake/help/latest/command/message.html"):打印出信息用于 debug。
16. [option](https://link.juejin.cn?target=https%3A%2F%2Fcmake.org%2Fcmake%2Fhelp%2Flatest%2Fcommand%2Foption.html "https://cmake.org/cmake/help/latest/command/option.html"):用于快速设置定义变量并赋值为对应的 bool 值,常被用于判断某些操作是否执行。
17. [find_package](https://link.juejin.cn?target=https%3A%2F%2Fcmake.org%2Fcmake%2Fhelp%2Flatest%2Fcommand%2Ffind_package.html%23id5 "https://cmake.org/cmake/help/latest/command/find_package.html#id5"):用于查找外界的 package,其实就是查找外界对应的 `<package>Config.cmake` 和 `Find<package>.cmake` 文件,这些文件里有外界包对应的变量信息以及库和头文件的各种路径信息。我们需要注意一些有关 `find_package` 命令查找 Config.cmake 路径的变量:
* `CMAKE_PREFIX_PATH` 变量是一个路径列表,CMake 会在这些路径中搜索包的 `Config.cmake` 文件。
* `<Package>_DIR` 变量是指向包的 `Config.cmake` 文件的路径。如果你手动设置了这个变量,那么 `find_package` 命令就可以找到包的信息。
同时他的一些常用参数如下:
* `CONFIG` :显式指定 find_package 去查找 `<package>Config.cmake` 文件,一般只要你在变量里面指定了 `<package>Config.cmake` 的路径,那么该参数填不填都没差别。我建议最好还是带上该参数比较好。
* `REQUIRED` :该参数表示如果没找到,那么直接产生 cmake 错误,退出 cmake 执行过程,如果没有 REQUIRED,则即使没找到也不会终止编译。
* `PATHS` :这个参数的效果和前面的变量类似,也是指定查找的路径。
* `COMPONENTS` :用于指定查找的模块,模块分离在不同的文件中,需要使用哪个就指定哪个模块。典型的就是使用 Qt 时的 cmake 代码,比如 `find_package(Qt5 COMPONENT Core Gui Widgets REQUIRED)` 。
* VERSION:可能有很多个不同版本的包,则需要通过该参数来指定,如:`find_package(XXX VERSION 1.2.3)`。
18. [include](https://link.juejin.cn?target=https%3A%2F%2Fcmake.org%2Fcmake%2Fhelp%2Flatest%2Fcommand%2Finclude.html "https://cmake.org/cmake/help/latest/command/include.html"):从文件或模块加载并运行 CMake 代码。我用这个命令实际上只是为了使用 [FetchContent](https://link.juejin.cn?target=https%3A%2F%2Fcmake.org%2Fcmake%2Fhelp%2Flatest%2Fmodule%2FFetchContent.html%23id1 "https://cmake.org/cmake/help/latest/module/FetchContent.html#id1") 这个 module 的功能,该功能是从 cmake3.11 开始支持的,使用该 module 前需要通过 include 命令加载该模块,命令如下:`include(FetchContent)`
19. [FetchContent](https://link.juejin.cn?target=https%3A%2F%2Fcmake.org%2Fcmake%2Fhelp%2Flatest%2Fmodule%2FFetchContent.html%23id1 "https://cmake.org/cmake/help/latest/module/FetchContent.html#id1"):这是一个模块功能,它用来从代码仓库中拉取代码,例如我要把最近写的日志库引入到当前的项目中使用(注意这中间不会有任何代理,所以拉取 GitHub 的仓库可能失败):
```
include(FetchContent)# 引入功能模块
FetchContent_Declare(
my-logger #项目名称
GIT_REPOSITORY https://github.com/ACking-you/my-logger.git #仓库地址
GIT_TAG v1.6.2 #仓库的版本tag
GIT_SHALLOW TRUE #是否只拉取最新的记录
)
FetchContent_MakeAvailable(my-logger)
add_excutable(main ${SRC})
# 链接到程序进行使用
target_link_libraries(main my-logger)
```
这样引入第三方库的好处显而易见,优点类似于包管理的效果了,但缺少了最关键的中心仓库来确保资源的有效和稳定。参考 golang 再做个 proxy 层级就好了。
同样可以拉取最新的 googletest 可以使用下列语句:
```
FetchContent_Declare(
googletest
GIT_REPOSITORY https://github.com/google/googletest.git
GIT_TAG release-1.12.1
GIT_SHALLOW TRUE
)
# For Windows: Prevent overriding the parent project's compiler/linker settings
set(gtest_force_shared_crt ON CACHE BOOL "" FORCE)
FetchContent_MakeAvailable(googletest)
target_link_libraries(main gtest_main)
```
20. [function/endfunction](https://link.juejin.cn?target=https%3A%2F%2Fcmake.org%2Fcmake%2Fhelp%2Flatest%2Fcommand%2Ffunction.html "https://cmake.org/cmake/help/latest/command/function.html") :在 cmake 中用于定义函数,复用 cmake 代码的命令。第一个参数为函数的名称,后面为参数的名称,使用参数和使用变量时一样的,但是如果参数是列表类型,则在传入的时候就会被展开,然后与函数参数依次对应,多余的参数被 `ARGN` 参数吸收。
更多较为常用的命令:
* [add_custom_command](https://link.juejin.cn?target=https%3A%2F%2Fcmake.org%2Fcmake%2Fhelp%2Flatest%2Fcommand%2Fadd_custom_command.html "https://cmake.org/cmake/help/latest/command/add_custom_command.html"):添加自定义规则命令,同样也是执行外界命令,但多了根据依赖和产物判断执行时机的作用。
* [install](https://link.juejin.cn?target=https%3A%2F%2Fcmake.org%2Fcmake%2Fhelp%2Flatest%2Fcommand%2Finstall.html "https://cmake.org/cmake/help/latest/command/install.html"):添加 install 操作。
* [string](https://link.juejin.cn?target=https%3A%2F%2Fcmake.org%2Fcmake%2Fhelp%2Flatest%2Fcommand%2Fstring.html "https://cmake.org/cmake/help/latest/command/string.html"):对 string 的所有操作,比如字符串替换啥的。
* [list](https://link.juejin.cn?target=https%3A%2F%2Fcmake.org%2Fcmake%2Fhelp%2Flatest%2Fcommand%2Flist.html "https://cmake.org/cmake/help/latest/command/list.html"):对 list 的所有操作,比如列表处理之类的。
* [foreach](https://link.juejin.cn?target=https%3A%2F%2Fcmake.org%2Fcmake%2Fhelp%2Flatest%2Fcommand%2Fforeach.html "https://cmake.org/cmake/help/latest/command/foreach.html"):cmake 中的 for 循环。
* ...
利用上述命令实现 Qt 开发中调用 uic 工具把 大量的 `.ui` 文件转化为 .cpp 和 .h 文件,并实现当 ui 文件更新时或 .cpp/.h 文件不存在时才创建对应的 .cpp/.h 文件。
```
# 函数功能实现
function(get_ui_source)
foreach (item ${ARGN})
set(UIC_EXE_PATH ${VCPKG_ROOT}/installed/x64-windows/tools/qt5/bin/uic.exe)
get_filename_component(name ${item} NAME_WLE)
string(PREPEND name "ui_")
set(output_h ${PROJECT_SOURCE_DIR}/ui_gen/${name}.h)
set(output_cpp ${PROJECT_SOURCE_DIR}/ui_gen/${name}.cpp)
file(TIMESTAMP ${item} ui_time)
# 当.h 文件已经存在时,仅当.ui 文件被更新了才重新生成.h 文件
if (EXISTS ${output_h})
file(TIMESTAMP ${output_h} h_time)
if (ui_time GREATER h_time)
execute_process(COMMAND ${UIC_EXE_PATH} ${item} -o ${output_h})
endif ()
else ()
execute_process(COMMAND ${UIC_EXE_PATH} ${item} -o ${output_h})
endif ()
# 当.cpp 文件已经存在时,仅当.ui 文件被更新了才重新生成.cpp 文件
if (EXISTS ${output_cpp})
file(TIMESTAMP ${output_cpp} cpp_time)
if (ui_time GREATER cpp_time)
execute_process(COMMAND ${UIC_EXE_PATH} ${item} -o ${output_cpp})
endif ()
else ()
execute_process(COMMAND ${UIC_EXE_PATH} ${item} -o ${output_cpp})
endif ()
endforeach ()
endfunction()
```
---
Henry 2023-01-29 【此文自用】修改、转载自:https://juejin.cn/post/7184793007302901820
守望之墓/电子骨灰盒https://www.bytecho.net/archives/ow.html2023-01-23T12:50:00.000Z### 来自上海网之易
> https://ow.blizzard.cn/article/news/2047?blzcmp=app
致各位亲爱的暴雪游戏玩家:
感谢您一直以来给予暴雪游戏产品的支持与厚爱,我们很荣幸能与大家共同携手走过 14 年的历程,一起创造并分享了难忘的游戏体验,再次向大家致以最衷心的感谢!
由于我们与合作方暴雪娱乐的协议期限即将届满,在中国大陆地区由上海网之易网络科技发展有限公司所运营的《魔兽世界》《炉石传说》《守望先锋》《暗黑破坏神 III》《星际争霸 II》《魔兽争霸 III:重制版》《风暴英雄》(以下统称“暴雪游戏产品”),将于 2023 年 1 月 24 日 0 时终止运营,现将终止中国大陆地区运营相关事项通知如下:
* 2022 年 11 月 23 日起,关闭暴雪游戏产品在战网以及客户端内的充值服务及用户注册入口。
* 在 2022 年 11 月 23 日至 2023 年 1 月 23 日期间,暴雪游戏产品的服务器将正常开放,《魔兽世界》“巨龙时代”内容更新、《炉石传说》“巫妖王的进军”以及《守望先锋》“归来”第 2 赛季内容更新将照常上线,用户可继续登录并体验游戏内容。同时,用户在账户中留存的战网点和虚拟货币将依旧可以在战网商城进行消耗。
* 2023 年 1 月 24 日 0 时起,正式停止暴雪游戏产品的运营,关闭战网登录以及所有游戏服务器,同时关闭客户端下载。
* 游戏服务器关闭后,各游戏内的所有账号数据及角色资料等(包括但不限于人物角色、剩余游戏时间、各游戏道具、素材、充值信息等)游戏数据将被封存。我们将按照法律法规的要求妥善处理游戏数据,保障用户合法权益。
* 针对玩家在游戏内已充值但未消耗的网络游戏虚拟货币以及付费购买且仍未失效的游戏时间(如有),我们将在暴雪游戏产品停止运营后开始安排退款,详情请关注与绑定“暴雪游戏服务中心”公众号。
以上所述,还请您周知并相互转告,如有任何疑义,请随时与网易暴雪游戏客服联系(在线支持:[www.battlenet.com.cn/support/zh/](http://www.battlenet.com.cn/support/zh/);联系电话:0571-28090163)。
我们对此次终止运营给您造成的不便深表歉意!我们十分感谢您的理解和原谅,也衷心期待您继续支持和关注!
上海网之易网络科技发展有限公司
2022 年 11 月 17 日
---
### 来自暴雪中国
亲爱的国服玩家们:
我们想通过今天这封信,对暴雪娱乐在国服地区的游戏服务状况向大家做一些说明。
我们明白,自从网易的相关公告发布以来,这段时间大家都很煎熬,而我们自己也深感忧虑。我们永远都把玩家放在第一位,无论各位来自世界的哪个角落。大家对未来的不确定感,也让我们这些已服务国服玩家社区 20 年的暴雪同事们感到很痛苦。
许多暴雪的同事都是游戏玩家。我们通过电子游戏结识了许多终生挚友,收获了许多珍贵回忆。这些游戏空间对我们来说意义重大,让我们能尽情享受乐趣,成为一个热爱暴雪游戏的玩家。我们非常理解游戏对人们有多重要。许多国服玩家也发来消息和邮件分享你们的感受,你们不能玩到最喜欢游戏的痛苦,你们与暴雪游戏、乃至暴雪早期经典游戏的共同成长经历,你们从那时起就一直是暴雪游戏的玩家。每封邮件读来都让我们唏噓感叹。
正是出于我们作为游戏玩家的个人体会,以及国服玩家向我们所表达的懊恼,我们上周再次与网易接触并寻求协助,以探讨将现有的,基于网易于 2019 年已同意既定条款的协议,顺延六个月,从而使大家得以不受干扰地继续游戏,也让暴雪继续探寻未来在国服地区合理而长远的发展道路。
不幸的是,网易并未在上周的顺延谈判后,接受我们关于顺延现有游戏服务协议的提议。因此我们将不得不遵照网之易停服公告于 1 月 23 日中止国服游戏服务。
---
### 守望之墓(电子骨灰盒)
本人 **2016 至今** 守望生涯之记录,鉴于其承载我和王者级人物二号的太多回忆,故留下其**电子骨灰盒**用于后人瞻仰,让众人铭记于 2016 年诞生之旷世绝唱!

“六年”生死两茫茫,不思量,自难忘。 千里孤坟,无处话凄凉。 纵使相逢应不识,尘满面,鬓如霜。
——江城子·乙卯正月二十日夜记梦 苏轼
**致 Blizzard!**
---
### 来自网易公众号 停服前的讣告
亲爱的暴雪游戏玩家:2023 年 1 月 24 日 0 时,由网之易代理的《魔兽世界》《炉石传说》《守望先锋》《暗黑破坏神 Ⅲ》《魔兽争霸 Ⅲ:重制版》《风暴英雄》《星际争霸》系列产品在中国大陆市场的所有运营将正式终止。届时,暴雪将关闭战网登录以及所有游戏服务器,同时关闭客户端下载。
相伴 14 年,说再见很难。我们一直清楚知道,对每个玩家,包括我们自己而言,所有的角色、账号、装备和好友列表,绝不仅仅是一串代码,而是我们的青春,我们的热血,我们的一段美好人生。所以,我们不会忘记对玩家的承诺,仍将尽最大努力,为暴雪国服玩家服务到最后一刻,与玩家共同走完最后一里路。我们将于停服后公布暴雪游戏产品的退款工作安排,请各位玩家关注“暴雪游戏服务中心”公众号。
与国服玩家相伴 14 年,除了感谢,我们更感荣幸。
感谢每个玩家对服务器的包容,对客服服务的理解,对黄金赛现场排队的耐心,甚至对暴雪游戏频道直播中的每一个广告都愿意忍受。
我们更荣幸,大家将人生最重要的青春时光,选择与我们共同度过。我们一起在游戏里与时间为敌,也在平凡的生活里打怪升级,一起创造不可复制的青春回忆。
我们永远记得,曾与每一个玩家在艾泽拉斯的世界里,迎战一个又一个强大的敌人;在炉石酒馆的闲暇中,思考、构筑、切磋牌技;在守望先锋和黑爪的战斗中,成为这个世界需要的英雄;也在庇护之地、在时空枢纽、在科普卢星区,书写篇章、挥洒热血。
这些美好的回忆,不会因停服而消逝,它们就像宝石一样,会在我们未来的平凡生活里闪闪发亮。这也是为什么我们由衷地希望,这次停服不是国服玩家的终点,而只是一次无奈的暂停。
**我们始终坚信,相逢的人总能再相逢。**衷心期待所有暴雪玩家重返国服的那一天。愿风指引我们的道路,愿星辰照亮我们前进的方向。
网易公司 1 月 23 日
---
***这个未来值得为之奋战!***
字节星球 Henry 2023-01-23
WePlanet现已发布!https://www.bytecho.net/archives/2105.html2022-08-20T08:09:00.000Z### WePlanet (Desktop) - 🚀适用于小型团体的协作系统
交流、工作、活动、分析、管理、审批...等的功能均集成于简约轻便的 **WePlanet(Desktop)**。
- 平台:Windows x64
- 开发环境:Visual Studio 2022
- 数据库:MySQL
- 语言:C++ 11
- 框架:Qt5.15.x
### 开发进度
**已完成:**
* [x] 用户系统
* [x] 考勤系统
* [x] 个人管理
* [x] 用户管理
* [x] 版本公告
* [x] 活动系统
* [x] 权限系统
* [x] 组织架构
* [x] Markdown 通知动态
* [x] 数据图表
* [x] 数据导出
* [x] 自动更新
* [x] 登录检测
* [x] ECharts 数据大屏
* [x] 认证系统
* [x] 好友系统(测试版)
* [x] 审批系统
* [x] 审批流程设计
**开发计划:**
* [ ] 积分商城
* [ ] 更多...
### 开发进度截图
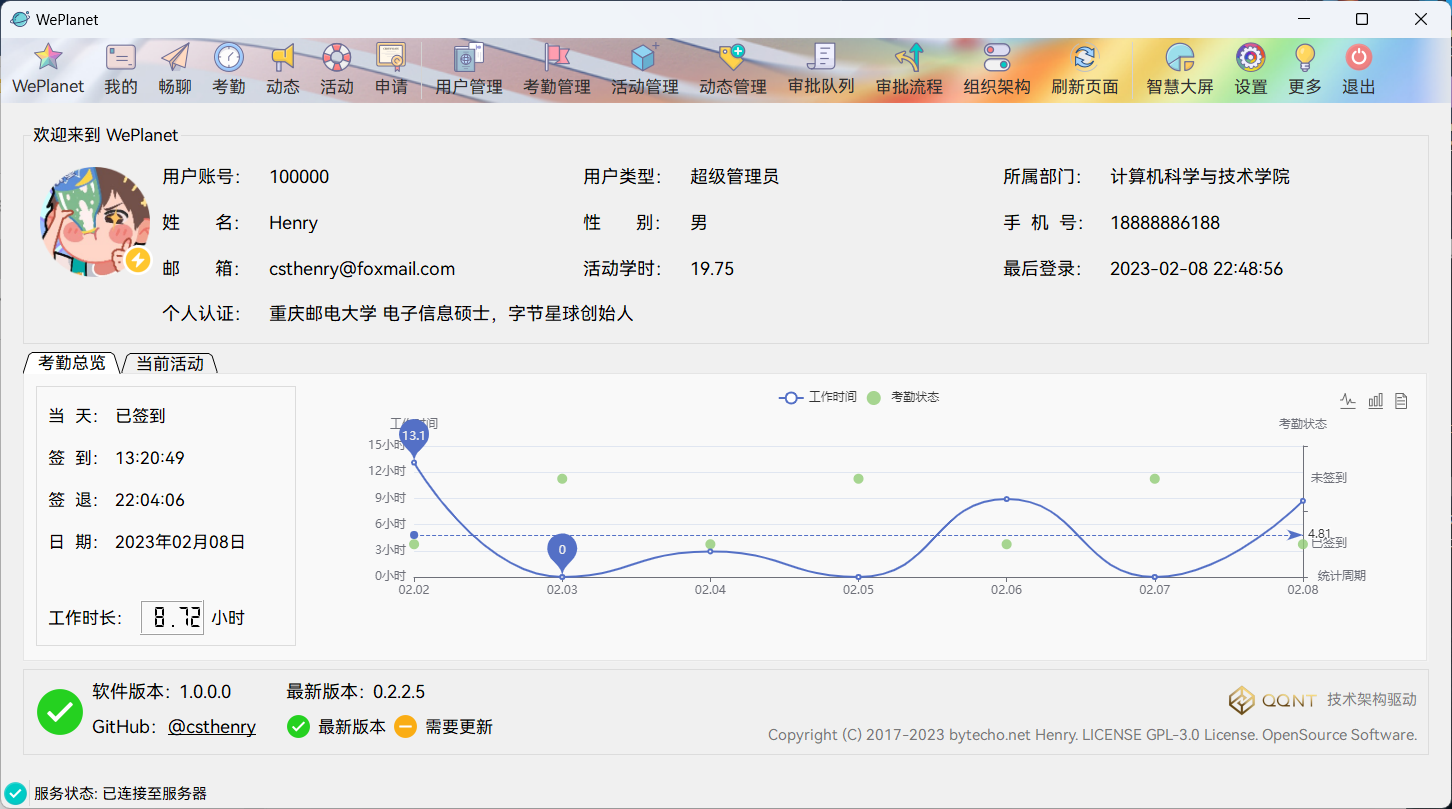
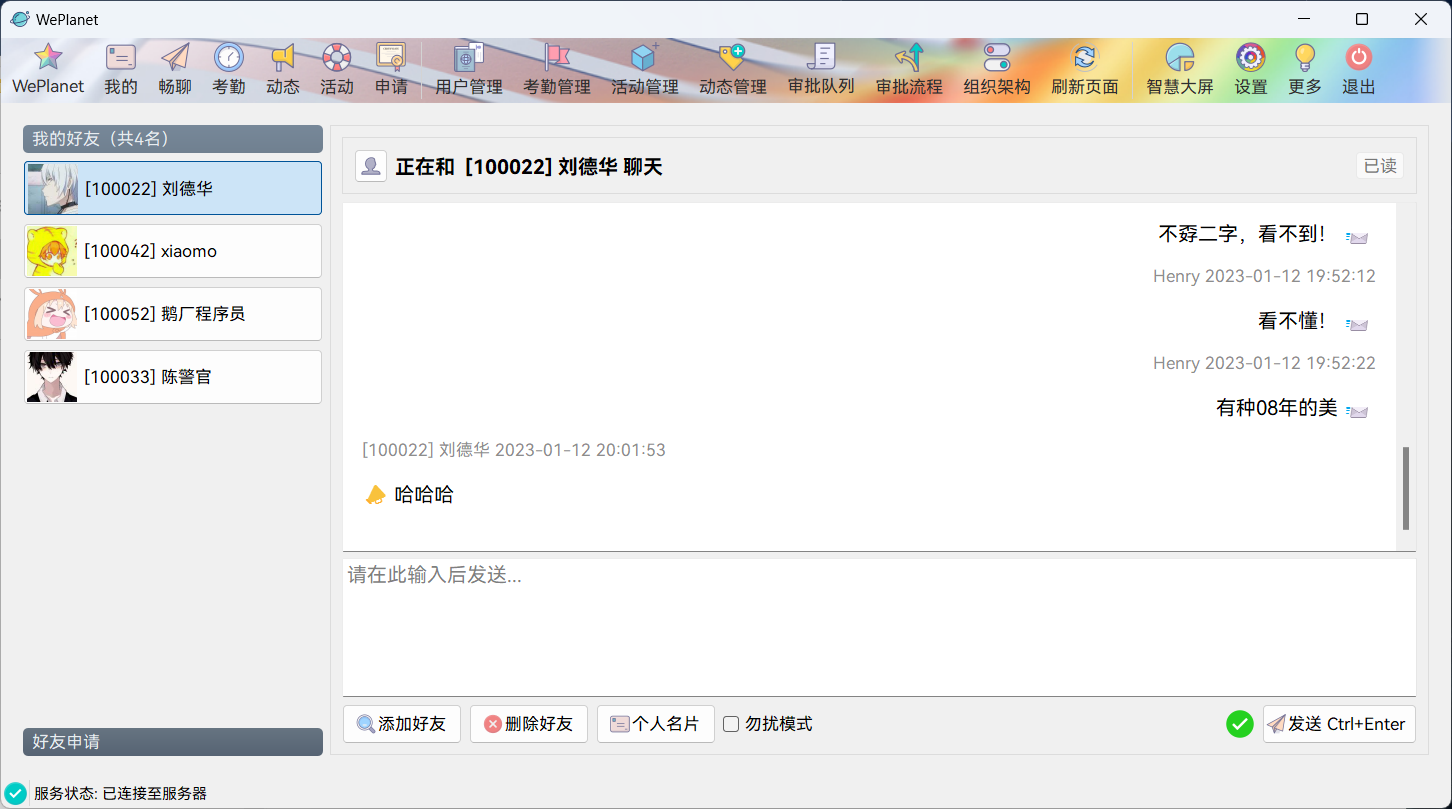
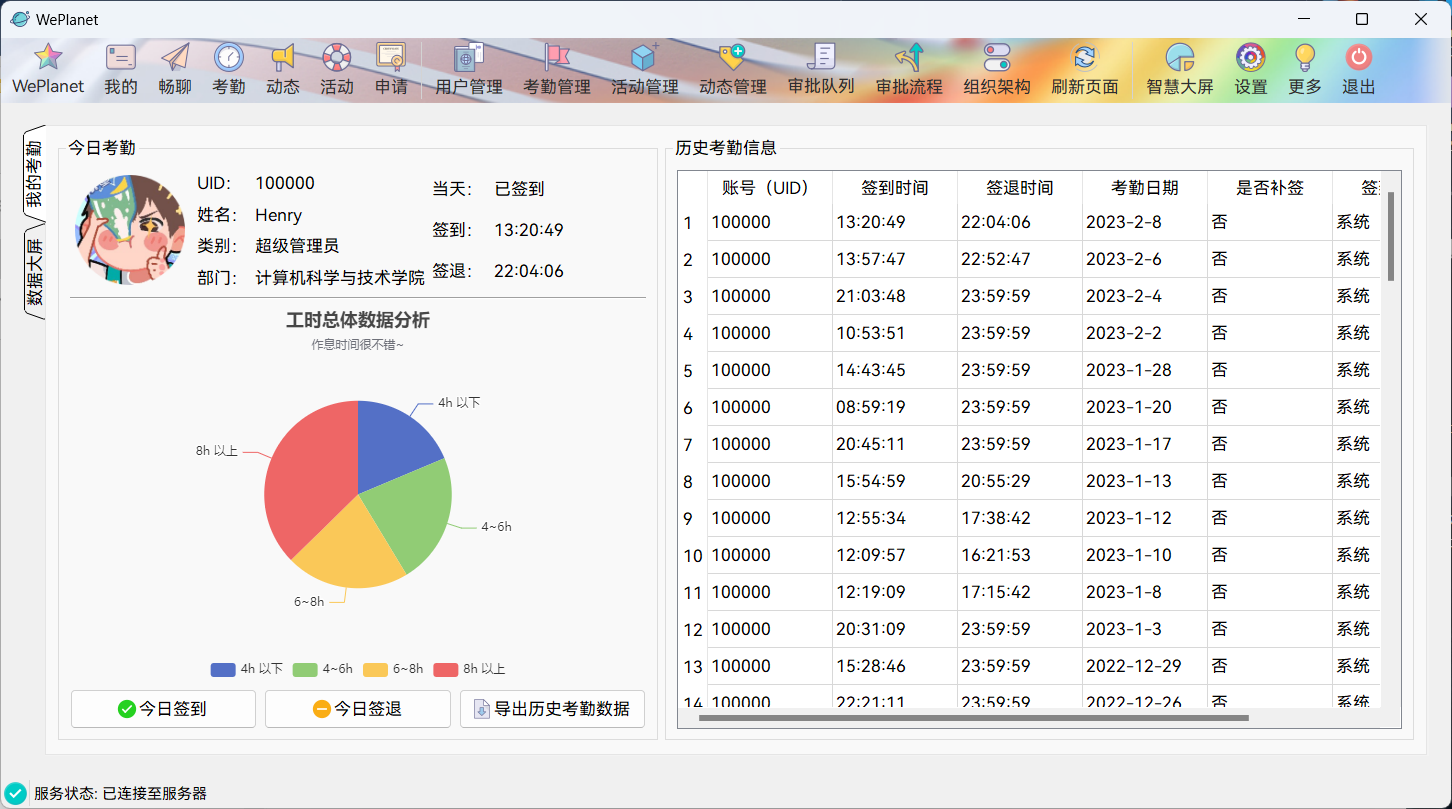
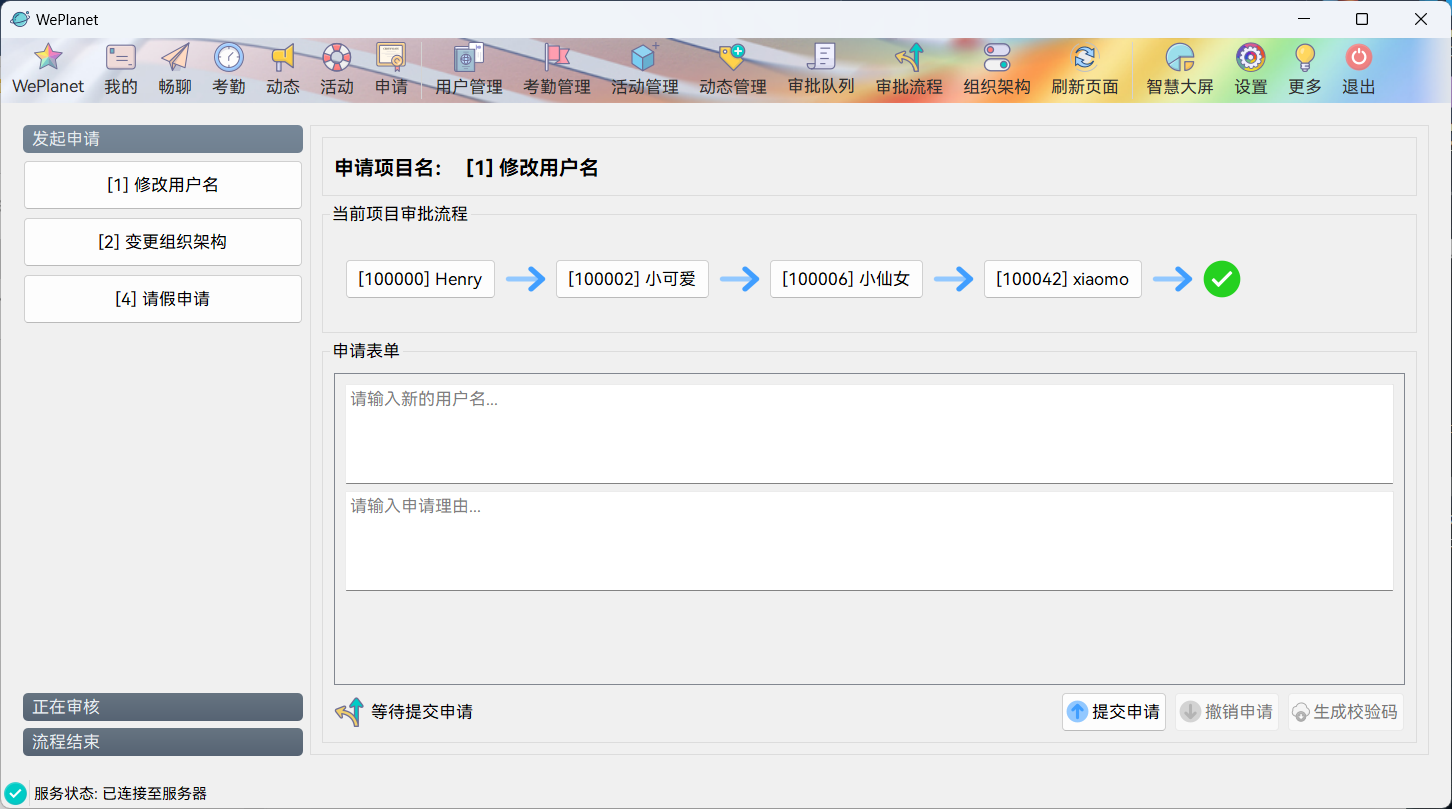
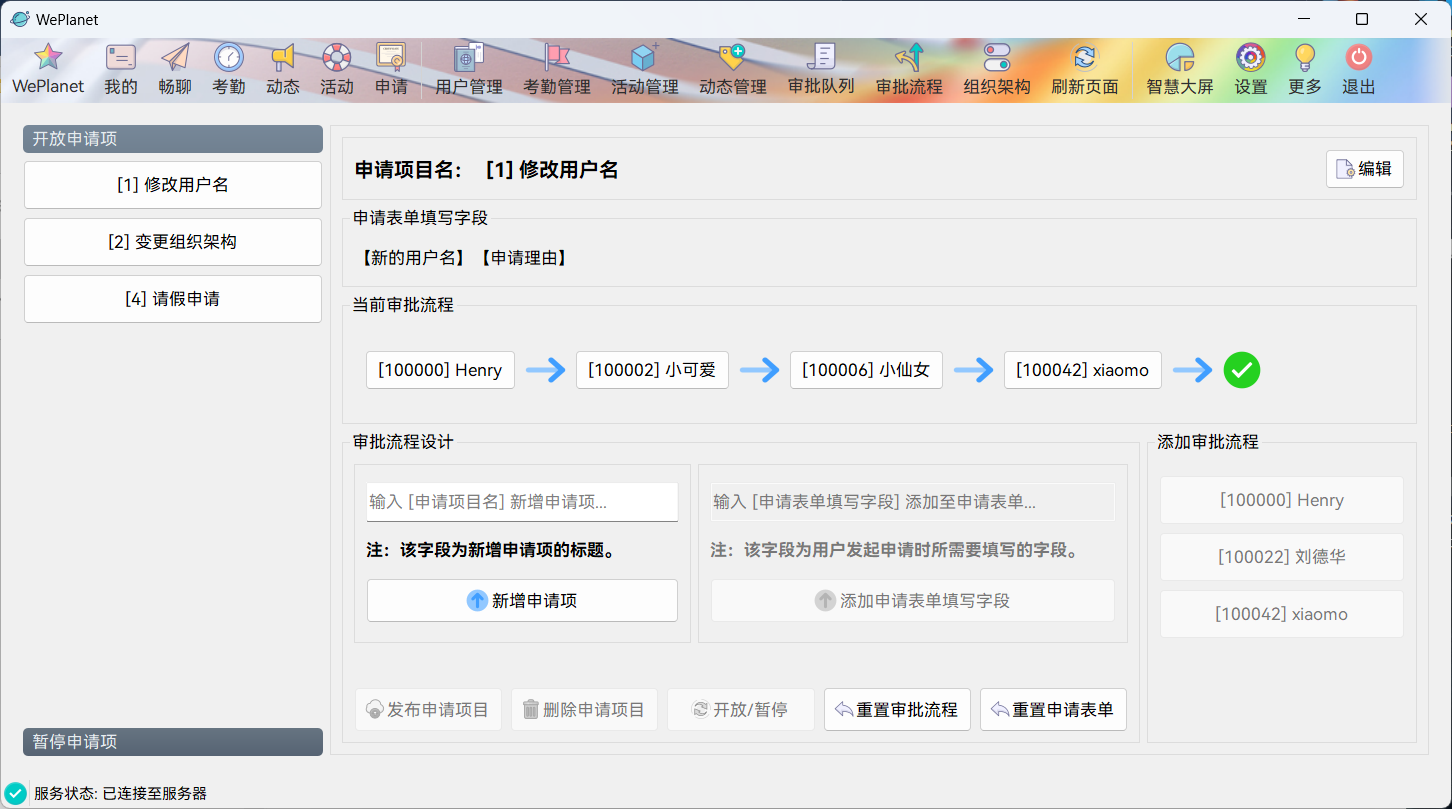
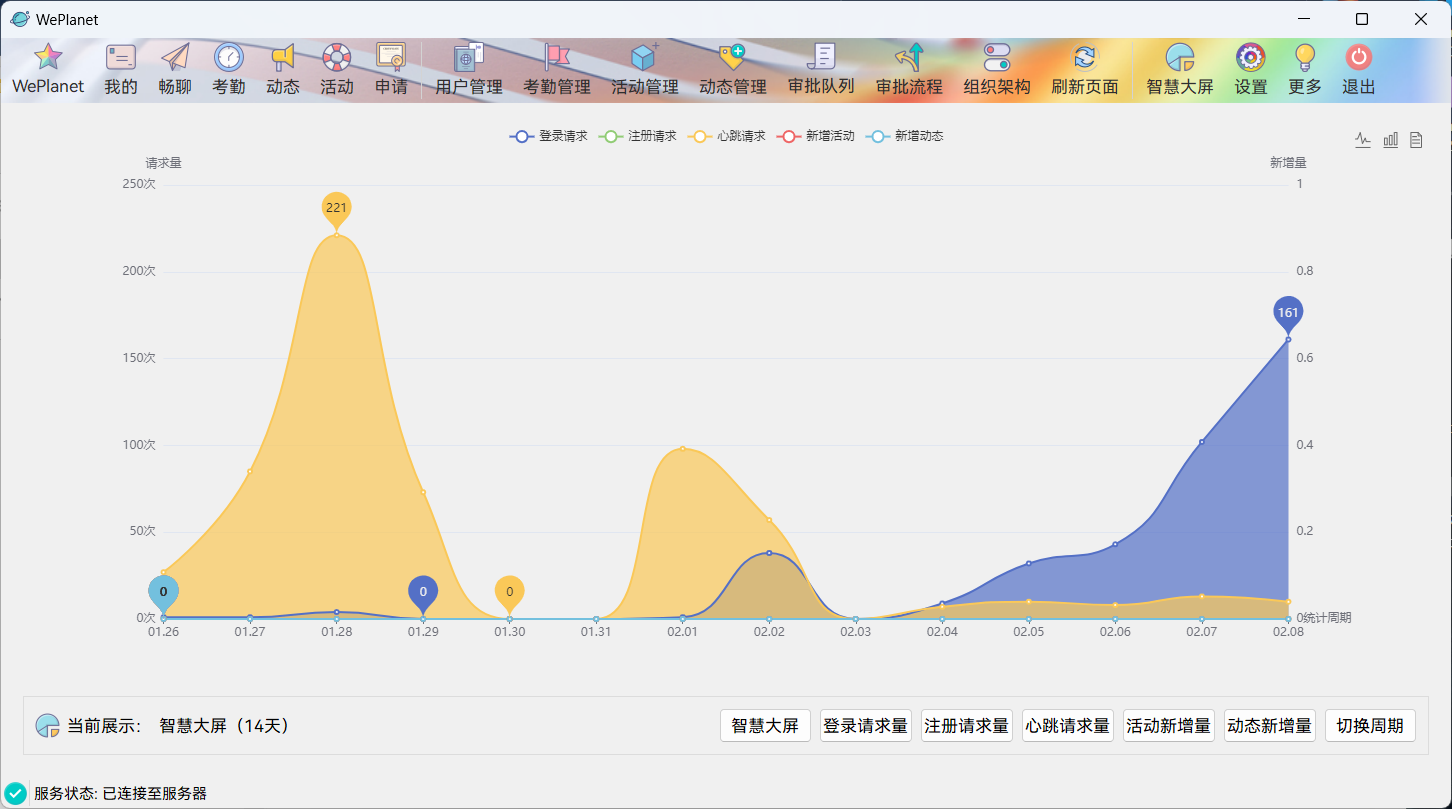
更多截图请查看:https://github.com/csthenry/weplanet-desktop/tree/master/screenshot
### 注意
项目已转换为 Visual Studio 项目,开发环境 Visual Studio 2022, 请使用 Visual Studio 2017+ 添加此项目。
在添加项目前,请先阅读:https://www.bytecho.net/archives/qt_mysql.html
### LICENSE
[GPL-3.0 License](https://github.com/csthenry/weplanet-desktop/blob/master/LICENSE)
### 🔥软件下载
[file href="https://github.com/csthenry/weplanet-desktop/releases/download/v1.1.0.0/WePlanet.exe"]WePlanet 典藏纪念版下载(Github 链接)[/file]
注:🔥**自动更新程序现已实装**,可下载安装后通过软件自动更新检测程序更新至最新版本。
**普通用户直接注册即可试用基本用户功能,评论区可申请试用管理员账号。**
[tip type="warning"]如无法正常运行或登录,请安装软件根目录下的运行环境,支持 Windows10 x64 以上系统。[/tip]
---
Copyright (C)字节星球 计算机科学与技术学院/软件工程学院
Copyright (C) 2017-2023 [字节星球](https://www.bytecho.net/) [Henry](https://www.bytecho.net/about.html)
简单选择排序和堆排序https://www.bytecho.net/archives/2090.html2022-08-05T14:22:00.000Z最近在全面学习数据结构,常用算法记录:简单选择排序和堆排序,简单选择排序的基本思想是每一趟在待排序元素中选取关键字最小的元素加入有序子序列,直到所有元素有序,总共进行 $n-1$ 趟。
堆排序的基本思想见文末图片。
简单选择排序为**不稳定**排序。
堆排序为**不稳定**排序。
**简单选择排序时间复杂度:**
时间复杂度:$O(n^2)$
空间复杂度:$O(1)$
**堆排序时间复杂度:**
一个节点每下降一层,最多只需要比较两次关键字。若树高度为 $h$,某节点在第 $i$ 层,则将这个节点向下调整最多只需要下降 $h-i$ 层,那么对比次数不超过 ${2}(h-i)$,$n$ 个节点的完全二叉树树高 $h = \left\lfloor {{{\log }_2}n} \right\rfloor + 1$。
将整棵树调整为大根堆,关键字比较次数不超过:
$$
\sum\limits_{{\rm{i}} = h - 1}^1 {{2^{i - 1}}2(h - i) = } \sum\limits_{{\rm{i}} = h - 1}^1 {{2^i}(h - i) = } \sum\limits_{j = 1}^{h - 1} {{2^{h - j}}j \le 2n\sum\limits_{j = 1}^{h - 1} {\frac{j}{{{2^j}}}} } \le 4n
$$
建堆的过程关键字的对比次数不超过 ${4}n$,建堆的时间复杂度:$O(n)$
`heapSort`总共需要 $n-1$ 趟,每一趟完成后都需要将根节点下坠,根节点最多下降 $h-1$ 层,因此,每一趟排序的复杂度不超过 $O(h)=O({{{\log }_2}n})$,总共 $n-1$ 趟,故总时间复杂度:$O(n{{{\log }_2}n})$
故堆排序的时间复杂度:$O(n)+O(n{{{\log }_2}n})=O(n{{{\log }_2}n})$
空间复杂度:$O(1)$
```cpp
#include <iostream>
using namespace std;
void swap(int &a, int &b);
void selectSort(int arr[], int n); //简单选择排序
void buildMaxHeap(int arr[], int len); //建立大根堆
void headAdjust(int arr[], int k, int len); //调整节点,使其较小节点下坠,使其符合大根堆的特性
void heapSort(int arr[], int len); //堆排序(基于大根堆)
int main()
{
int arr[] = {5, 7, 12, 6, 2, 0, 8, 15, 1, 11}, heap_arr[] = {-1, 5, 7, 12, 6, 2, 0, 8, 15, 1, 11};
int length = (int)(sizeof(arr) / sizeof(int)); //数组长度
selectSort(arr, length);
for(auto item:arr)
cout << item << " ";
cout << endl;
heapSort(heap_arr, length);
for(int i = 1; i < length + 1; i++)
cout << heap_arr[i] << " ";
return 0;
}
void swap(int &a, int &b)
{
int temp = a;
a = b;
b = temp;
}
void selectSort(int arr[], int n)
{
for (int i = 0; i < n - 1; i++) //进行n-1次即可,最后一个数必然是最大的
{
int min = i;
for (int j = i + 1; j < n; j++) //从i后面一个数开始,找到一个最小的数
{
if (arr[j] < arr[min])
min = j; //记录最小数的下标
}
swap(arr[i], arr[min]); //将最小数与i位置的数交换
}
}
void buildMaxHeap(int arr[], int len)
{
for (int i = len / 2; i > 0; i--) //从最后一个分支节点开始调整,0为暂存节点
headAdjust(arr, i, len);
}
void headAdjust(int arr[], int k, int len)
{
arr[0] = arr[k]; //将当前节点暂存给arr[0]
for (int i = 2 * k; i <= len; i *= 2) //沿值较大的节点向下查找
{
if(i < len && arr[i] < arr[i + 1]) //i < len 保证当前节点有右孩子
i++; //记录左右子节点中较大的节点
if(arr[0] >= arr[i])
break; //如果当前节点大于等于左右子节点,则不需要调整
else{
arr[k] = arr[i]; //将左右子节点中较大的节点放入当前双亲节点
k = i; //替换为较大的节点,进入下一次循环,看是否满足大于左右孩子的条件
}
}
arr[k] = arr[0]; //将待调整的节点的值放入最终位置
}
void heapSort(int arr[], int len)
{
buildMaxHeap(arr, len); //建立大根堆
for (int i = len; i > 1; i--)
{
swap(arr[1], arr[i]); //堆顶和堆底交换,使堆底元素最大,注意堆顶是arr[1],arr[0]是暂存节点
headAdjust(arr, 1, i - 1); //调整剩余的堆(i及其后面的序列已经有序),让堆顶元素下坠
}
}
```

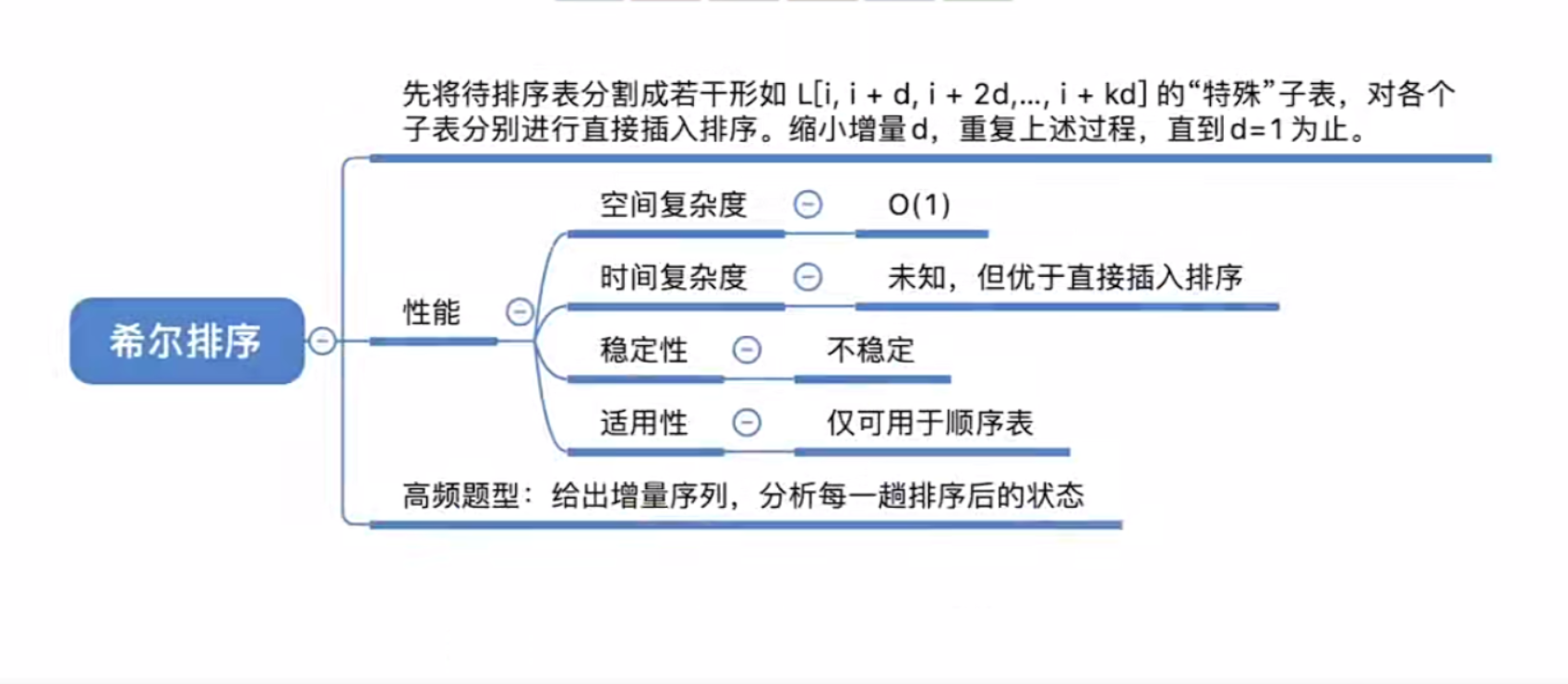
希尔排序https://www.bytecho.net/archives/2087.html2022-08-04T14:13:00.000Z最近在全面学习数据结构,常用算法记录:希尔排序,基本思想是选定一个增量 $d<n$,将元素按此增量分组(所有相距 $d$ 的元素为一组),然后在各个子序列内进行插入排序,完成后缩小增量 $d'(d'<d)$,如此反复操作,直到增量 $d = 1$ 为止,此时就成了标准的插入排序,但此时大部分元素已经有序,只需要少量操作,甚至不用操作即可完成排序。该排序算法为**不稳定**排序。
希尔排序还是比较绕的,需要多看看,多画一画。
最坏时间复杂度:$O(n^2)$
$n$ 在某范围内可达:$O(n^{1.3})$
目前无法用数学手段证明确切的时间复杂度。
```
#include <iostream>
using namespace std;
void shellSort(int arr[], int n);
int main()
{
int arr[] = {-1, 5, 7, 12, 6, 2, 0, 8, 15, 1, 11};
int length = (int)(sizeof(arr) / sizeof(int)); //数组长度
shellSort(arr, length);
for (int i = 1; i < length; i++)
cout << arr[i] << " ";
return 0;
}
void shellSort(int arr[], int n)
{
int d, i, j;
//arr[0]为暂存单元
for (d = n / 2; d > 0; d /= 2) //d为步长
{
for (i = d + 1; i <= n; i++) //从子表中第二个元素开始
if(arr[i] < arr[i - d]) //小于子序列前一项
{
arr[0] = arr[i]; //暂存待插入元素
for (j = i - d; j > 0 && arr[0] < arr[j]; j -= d)
arr[j + d] = arr[j]; //向后移动,为待插入元素腾出空位
arr[j + d] = arr[0]; //插入暂存元素
}
}
}
```
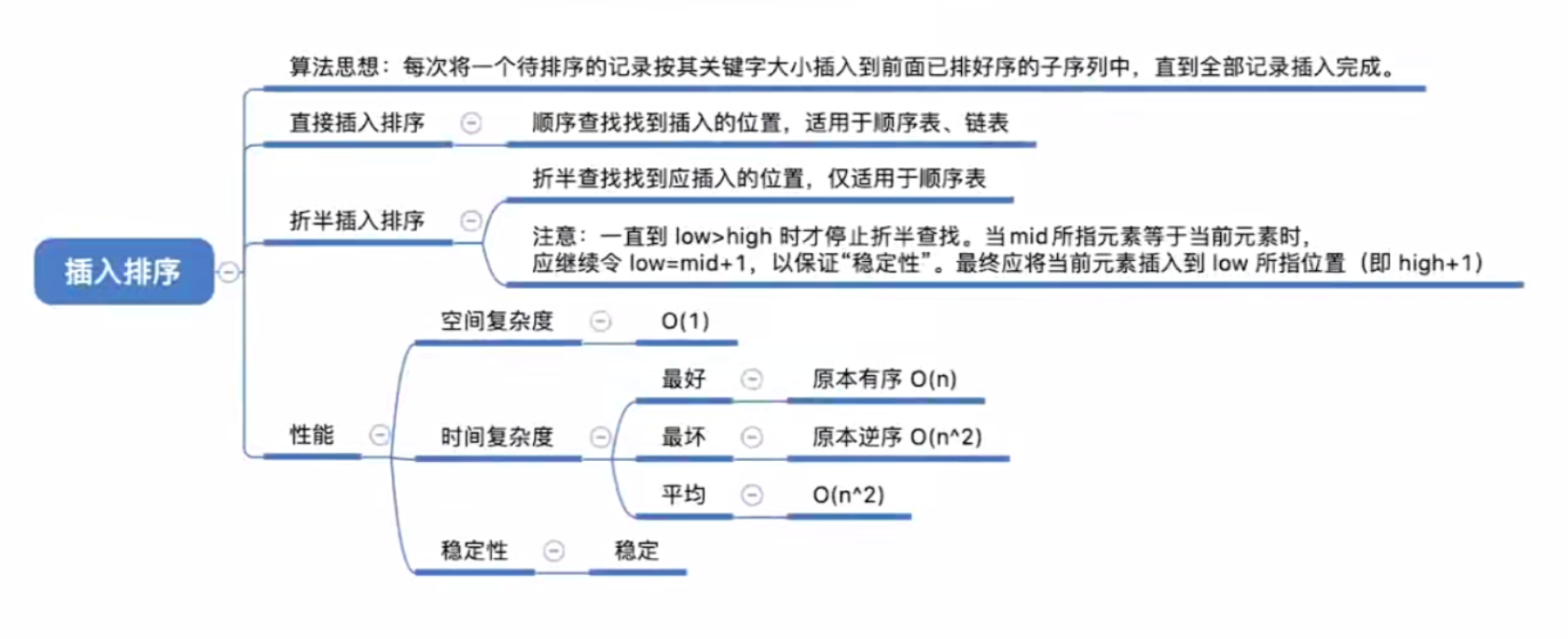
插入排序https://www.bytecho.net/archives/2078.html2022-08-03T14:08:00.000Z最近在全面学习数据结构,常用算法记录:插入排序,基本思想是将待排序的记录按其关键字的大小逐个插入到一个有序序列(通常为左半部分),直到所有记录插入完成,是一种**稳定**排序。
空间复杂度:$O(1)$
平均时间复杂度:$O(n^2)$
```cpp
#include <iostream>
using namespace std;
//直接插入排序(含哨兵)优点:不用判断j>=0,哨兵即为循环结束标志
void insertSort_1(int arr[], int n);
//直接插入排序(不含哨兵)
void insertSort_2(int arr[], int n);
//折半(二分)插入排序 对直接插入排序的优化
void insertSort_3(int arr[], int n);
int main()
{
int arr[] = {-1, 5, 7, 12, 6, 2, 0, 8, 15, 1, 11}, arr_2[] = {-1, 5, 7, 12, 6, 2, 0, 8, 15, 1, 11}, arr_normal[] = {5, 7, 12, 6, 2, 0, 8, 15, 1, 11};
int length = (int)(sizeof(arr) / sizeof(int)); //数组长度
insertSort_1(arr, length);
insertSort_2(arr_normal, length - 1);
for (int i = 1; i < length; i++)
cout << arr[i] << " ";
cout << endl;
for(auto item:arr_normal)
cout << item << " ";
cout << endl;
insertSort_3(arr_2, length);
for (int i = 1; i < length; i++)
cout << arr_2[i] << " ";
return 0;
}
void insertSort_1(int arr[],int n)
{
int i, j;
for (i = 2; i < n; i++) //从第二个元素开始,arr[0]为哨兵
{
if(arr[i] < arr[i - 1]) //arr[i - 1]为上一个有序序列中的最大元素
{
arr[0] = arr[i];
for (j = i - 1; arr[0] < arr[j]; --j) //当前元素若小于或等于哨兵元素,则停止移动,哨兵插入该位置后
arr[j + 1] = arr[j]; //往后移,为待插入元素腾出空位
arr[j + 1] = arr[0]; //将哨兵插入
}
}
}
void insertSort_2(int arr[],int n)
{
int i, j, temp;
for (i = 1; i < n; i++) //从第二个元素开始,arr[0]为哨兵
{
if(arr[i] < arr[i - 1]) //arr[i - 1]为上一个有序序列中的最大元素
{
temp = arr[i]; //临时存储待插入元素
for (j = i - 1; j >= 0 && temp < arr[j]; --j) //当前元素若小于或等于待插入元素,则停止移动,待插入元素插入该位置后
arr[j + 1] = arr[j]; //往后移,为待插入元素腾出空位
arr[j + 1] = temp; //待插入元素插入
}
}
}
void insertSort_3(int arr[], int n)
{
int i, j, low, high, mid;
for (i = 2; i < n; i++)
{
arr[0] = arr[i]; //待插入元素存入哨兵节点
low = 1, high = i - 1; //折半查找的区域
while(low <= high){
mid = (low + high) / 2;
if(arr[mid] > arr[0])
high = mid - 1; //查找左半部分
else
low = high + 1; //查找右半部分,同时当arr[mid]==arr[0]时,继续在mid右方查找插入位置,保证算法稳定性
}
for (j = i - 1; j >= high + 1; j--) //循环大于哨兵的所有元素,均往后移动一位
arr[j + 1] = arr[j]; //往后移,为待插入元素腾出空位
arr[high + 1] = arr[0]; //待插入元素插入
}
}
```
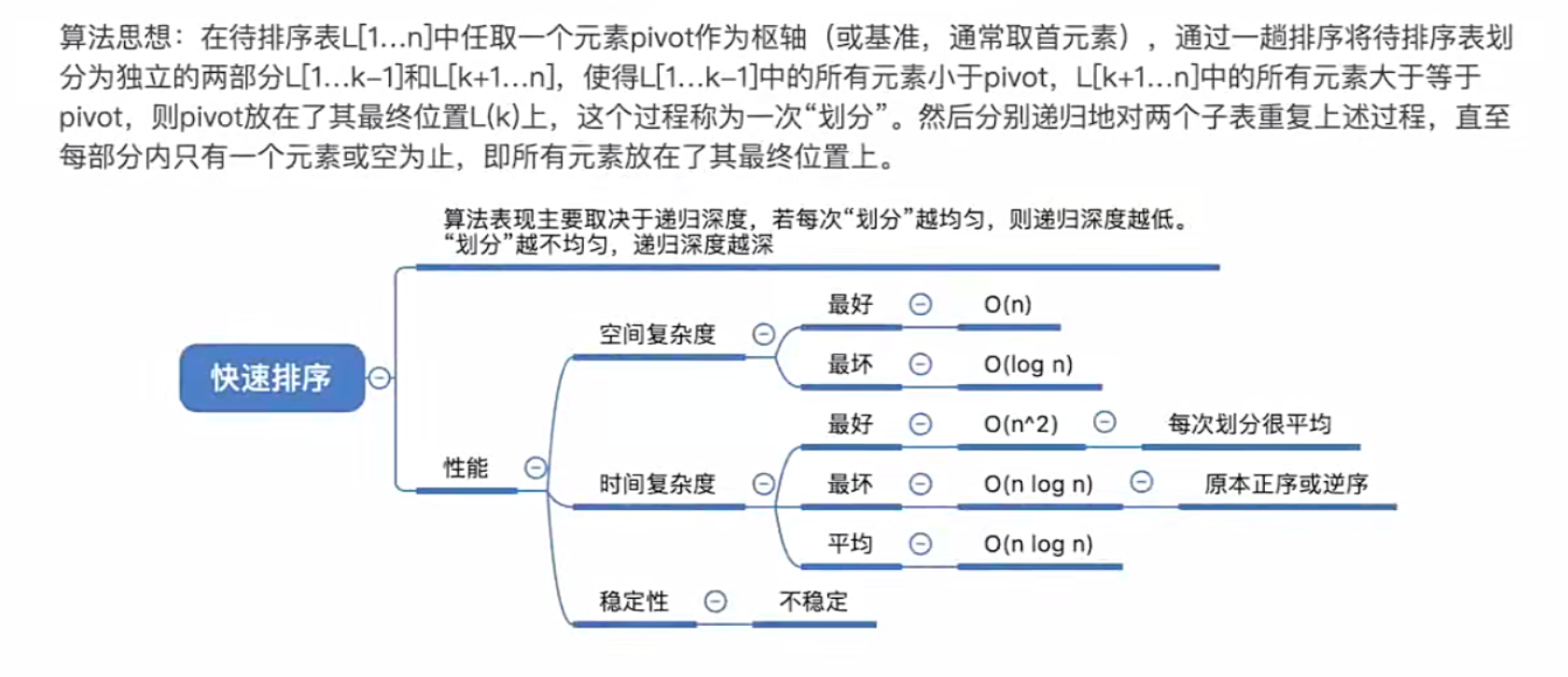
快速排序https://www.bytecho.net/archives/2075.html2022-08-03T12:47:00.000Z最近在全面学习数据结构,常用算法记录:快速排序,即交换排序的一种,是对冒泡排序的一种改进,是一种**不稳定**排序。
平均时间复杂度:$O(nlogn)$
最坏时间复杂度(退化至冒泡排序):$O(n^2)$
```cpp
#include <iostream>
using namespace std;
//快速排序
void quickSort(int arr[], int low, int high);
void quickSort_another(int *arr, int left, int right);
//划分函数
int partition(int arr[], int low, int high);
int main()
{
int arr[] = {5, 2, 4, 6, 1, 3};
quickSort(arr, 0, 5);
for(auto cur:arr)
cout << cur << " ";
cout << endl;
quickSort_another(arr, 0, 5);
for(auto cur:arr)
cout << cur << " ";
return 0;
}
int partition(int arr[], int low, int high)
{
int pivot = arr[low]; //第一个元素作为基准
while(low < high) //low == high时结束
{
while(low < high && arr[high] >= pivot)
--high;
arr[low] = arr[high]; //此时arr[high]小于基准元素
while (low < high && arr[low] <= pivot)
++low;
arr[high] = arr[low]; //此时arr[low]大于基准元素
}
arr[low] = pivot; //此时low == high
return low; //返回基准元素的下标
}
void quickSort(int arr[], int low, int high)
{
if(low < high)
{
int pivot_pos = partition(arr, low, high);
quickSort(arr, low, pivot_pos - 1); //对基准元素左边的数组进行快速排序
quickSort(arr, pivot_pos + 1, high); //对基准元素右边的数组进行快速排序
}
}
//写法二
void quickSort_another(int *arr, int left, int right)
{
if (left >= right)
return;
int pivot = arr[left];
int i = left + 1, j = right;
while (i <= j)
{
while (i <= right && arr[i] < pivot)
i++;
while (j >= left && arr[j] > pivot)
j--;
if (i <= j)
{
int temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
i++;
j--;
}
}
arr[left] = arr[j];
arr[j] = pivot;
quickSort_another(arr, left, j - 1);
quickSort_another(arr, j + 1, right);
}
```
Web使用HarmonyOS字体的压缩方案https://www.bytecho.net/archives/2042.html2022-07-11T04:10:00.000Z### HarmonyOS 字体
> https://developer.harmonyos.com/cn/docs/design/font-0000001157868583
通过研究用户在不同场景下对多终端设备的阅读反馈,综合考量不同设备的尺寸、使用场景等因素,同时也考虑用户使用设备时因视距、视角的差异带来的字体大小和字重的不同诉求,我们为 HarmonyOS 设计了全新系统默认的字体——HarmonyOS Sans(即鸿蒙字体)。

!!!
<center>HarmonyOS 字体效果</center>
!!!
通过 BILIBILI(哔哩哔哩)主站的使用效果来看,能明显发现 HarmonyOS 字体在 Windows 低分辨率`pixel-ratio < 1.5`屏幕上显示更加细腻。
### 网页加载速度的影响
如果需要全站使用同一种字体,那么我们或许需要同时加载 Regular、Medium、Bold 等不同字重的字体文件,这里给一个参考:
HarmonyOS_Sans_SC_Regular.ttf 文件大小高达 8068KB,注意,这仅仅是 Regular。
所以,如果不对字体文件进行压缩,将其作为 Web 字体是不合理的,这将极大拉缓网页加载速度,严重影响用户体验。
### 字体压缩
#### FontTools
> What is this?
fontTools is a library for manipulating fonts, written in Python. The project includes the TTX tool, that can convert TrueType and OpenType fonts to and from an XML text format, which is also called TTX. It supports TrueType, OpenType, AFM and to an extent Type 1 and some Mac-specific formats. The project has an [MIT open-source licence](https://github.com/fonttools/fonttools/blob/main/LICENSE).
Among other things this means you can use it free of charge.
[User documentation](https://fonttools.readthedocs.io/en/latest/) and [developer documentation](https://fonttools.readthedocs.io/en/latest/developer.html) are available at [Read the Docs](https://fonttools.readthedocs.io/).
#### 如何压缩
借助以上工具,我们可以将 unicode 分为多个片段来对字体文件进行压缩:
| **字符集** | **字数** | **Unicode 编码** |
| -- | -- | -- |
| 拉丁字母 | -- | 0000-007F,0080-00FF等 |
| 基本汉字 | 20902 字 | 4E00-9FA5 |
| 中文字符 | -- | 3002,FF1F等 |
我们只需要对这两万多个基本汉字进行分段即可,至于数字、拉丁字母等,其实并不会过多影响字体文件大小。
将 unicode 合理分段后,使用 fonttools subset 对字体进行压缩,命令如下:
```shell
pyftsubset ./HarmonyOS_Sans_SC_Bold.ttf --unicodes-file=./unicodes.txt --with-zopfli --flavor=woff2
# 参数说明
# pyftsubset <PATH> # 待压缩字体文件路径
# --unicodes-file=<PATH> # unicode.txt 文件路径
# --with-zopfli # 使用 Google 压缩算法
# --flavor=<TYPE> # 输出字体格式
```
我们将 unicode 写入 unicode.txt 文件中,使用 `--unicodes-file=<PATH>`即可使用。
待所有字体压缩完成后,我们在 CSS 中使用 `unicode-range`属性来调用对应 unicode 区域的字体文件。
具体效果可参考本站 (Windows 且`pixel-ratio < 1.5`环境下)的字体显示情况。
---
字节星球 Henry 2022-07-11 **未经许可 严禁转载!**
https://www.bytecho.net/archives/2042.html
字节星球关于在评论区等位置展示IP属地的公告https://www.bytecho.net/archives/2032.html2022-07-08T07:50:00.000Z字节星球为工信部、公安部备案网站,有责任、有义务管理字节星球网站环境。
**为维护真实有序的讨论氛围,净化网络环境,减少恶意造谣、恶意广告等不良行为**,字节星球拟在评论区、留言板等位置展示账号 IP 属地,相关功能即日起进行测试,将根据测试情况逐步在其他场景全量上线。
平台展示的账号 IP 属地为用户最近一次发布评论时的网络位置,境内展示到省(区、市),境外展示到国家(地区)。
账号 IP 属地以运营商提供信息为准,相关展示**不支持手动开启或关闭**。
***注:站内认证用户不对外展示 IP 属地。***
**列举部分曾因发布过违规评论而被封禁的 IP 地址:**
106.112.178.237
171.110.238.94
60.172.247.147
117.30.167.48
171.210.201.165
113.116.216.178
139.162.57.142
171.110.239.142
...
---
字节星球 2022-07-08
MATLAB简明教程#1https://www.bytecho.net/archives/2021.html2022-07-07T09:54:00.000Z### MATLAB 入门之旅
> 若能熟练运用 MATLAB,无疑是开启了探索宇宙间万物之本源的大门。——Henry@(捂嘴笑)
#### 进入 MATLAB
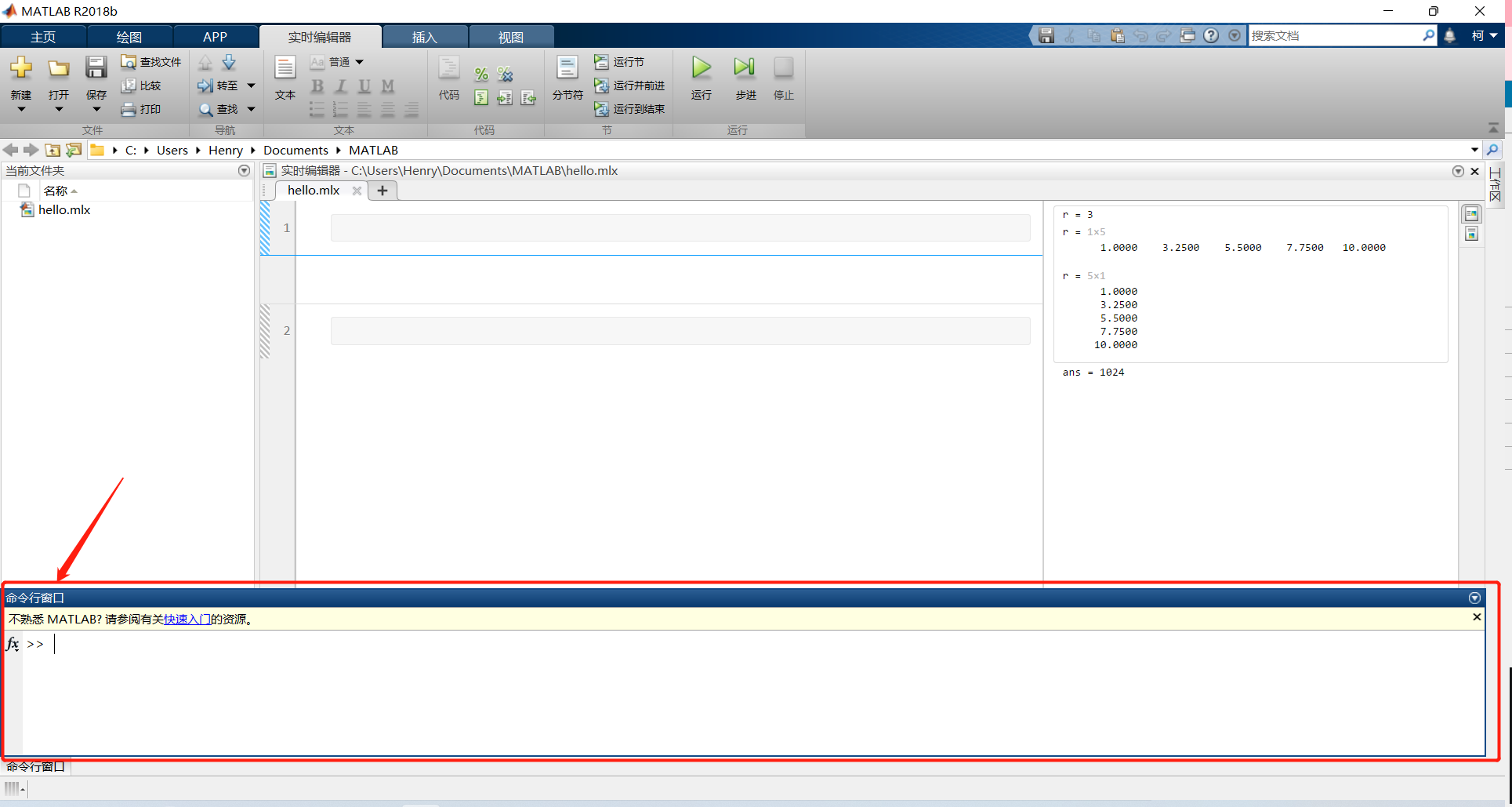
很好,当我们打开 MATLAB 后,最醒目的部分即是**命令行窗口**,我们试着在其中输入一些简单的命令,开始学习 MATLAB。
#### 基本命令
##### 简单计算
不同于其他高级语言(C++,Java,Python 等),MATLAB 不需要严格的变量定义,试着在**命令行窗口**中输入 `6*8` 并且运行,你会发现 MATLAB 输出了一个名为 ans 的变量值,这即是 `6*8` 的运算结果。
##### 定义变量
要在 MATLAB 中定义变量同样简单,试试以下语句:
```matlab
m = 3 * 5
```
这样就成功定义了一个名为 m 的变量。
再来看看赋值运算符,和我们学习的高级语言一样,它就是一个简单的等号:
```matlab
m = m + 1
```
不用惊喜,它的效果和 C++ 中一样,m 的值被改变为了 `m 本身 + 1`。
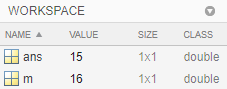
此时,我们打开 MATLAB 程序右侧的**工作区**,你会发现 ans 变量和我们定义的 m 变量都惊喜的出现在了其中,工作区显示了该变量的名称、值、大小和类型,非常醒目。
##### 语法对比
需要注意的是,或许我们已经发现,之前的命令中似乎不同于 C++,它并没有以分号结尾,事实上,分号在 MATLAB 中的作用于 C++ 等不太一样。
在命令的末尾添加分号将抑制输出,但仍会执行该命令,正如您在工作区中所看到的。当您输入命令而没有以分号结尾时,MATLAB 将会在命令提示符下显示结果(直接执行完成该命令)。
介绍一个小技巧,用过 Linux 终端的朋友应该很熟悉:你可以按键盘上的向上箭头键重新调用以前的命令。
请注意,要执行此操作,**命令行窗口**必须为活动窗口。
##### 保存和加载变量
您可以使用 `save` 命令将工作区中的变量保存到称为 MAT 文件的 MATLAB 特定格式文件中。
要将工作区保存到名为 `foo.mat` 的 MAT 文件中,请使用命令:
```
>> save foo
```
使用 `load` 命令从 MAT 文件加载变量。
```
>> load foo
```
加载完成后,变量 `data` 会在工作区中列出。你可以通过输入变量的名称来查看任何变量的内容。
```
myvar //你的变量名
```
**Tips:**
使用 `clear` 将工作区清空。
`clear` 函数清理工作区而`clc` 命令清理**命令行窗口**。
好,今天就先介绍到这里。
---
字节星球 Henry 2022-07-07 **未经允许,严禁转载!**
https://www.bytecho.net/archives/2021.html
解决Qt5无法连接MySQL数据库的问题https://www.bytecho.net/archives/qt_mysql.html2021-12-13T14:55:00.000Z### 引言
我最近打算开一个新项目,会用到 Qt5 和 MySQL,没想到刚开始就遇到了问题...
```
QSqlDatabase: QMYSQL driver not loaded
QSqlDatabase: available drivers: QSQLITE QODBC QODBC3 QPSQL QPSQL7
```
大体意思就是,这个 QSqlDatabase 里面压根就没有 QMySQL 这个驱动,在我印象中 Qt 肯定是自带了 MySQL 驱动的,搜索了一下知道了原因,在老版本的 Qt 中(5.9 还是 5.12?)在 `C:\Qt\Qt5.xx\5.xx\mingwxx_xx\plugins\sqldrivers` 这个目录下,有 qsqlmysql.dll 这个文件,我这边当然是没有了...所以 MySQL 肯定连不上了,既然没有那只能自己编译了,不可能去网上找吧,不同版本的文件也不同。
**注意:不同版本的 MySQL 里面包含不同的 libmysql.dll,不同的 libmysql.dll 必须和配套的 qsqlmysqld.dll (debug 版)或 qsqlmysql.dll(release 版) 一起才能正常工作!**
### Qt MySQL 驱动构建(使用 MinGW 编译套件)
#### 准备
编译前,请确认以下几点:
1. 你的 Qt 安装时是否选择了 Sources。
2. 你的 Qt 安装时是否选择的 64 位的 MinGW。
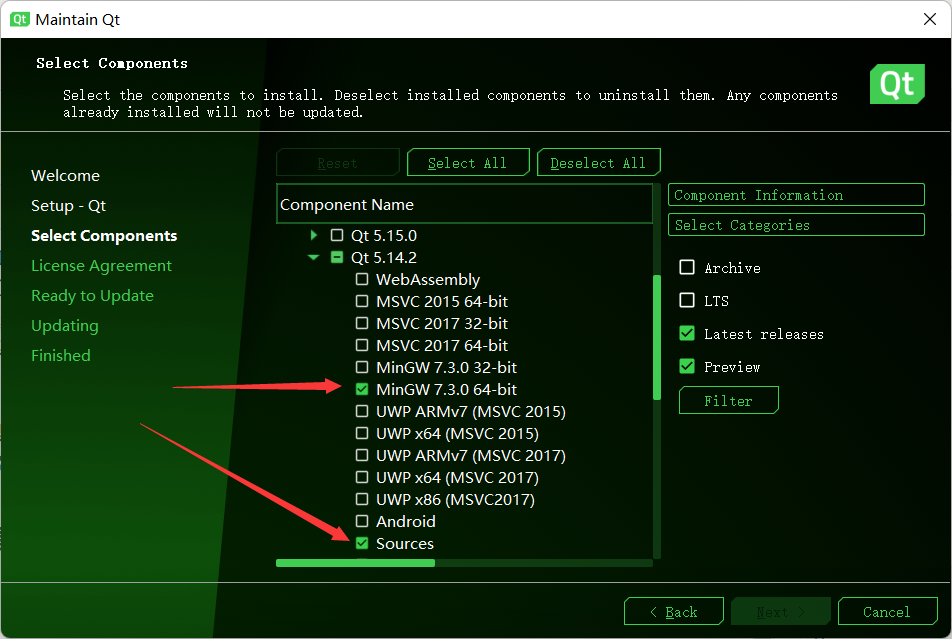
很多人应该没有选择 Sources 这一项,问题不大,在控制面板-> 卸载程序中找到 Qt 右键选择更改,自行添加 Sources 这个选项,具体做法可以借助搜索引擎,不怕麻烦的也可以直接重新按要求安装 Qt。
然后确定一下你的 `C:\Qt\Qt5.14.2\5.14.2\mingw73_64\plugins\sqldrivers` 文件夹里是否如我描述的那样没有 qsqlmysql.dll 文件,然后再开始下一步。
#### 编译
添加 Qt mingw 64 的环境变量,既然你都接触 Qt 了,环境变量对你来说应该是很熟悉的字眼了,就不说明怎么添加了,分别要添加的路径是:
```
C:\Qt\5.14.2\mingw73_64\bin\
C:\Qt\Tools\mingw730_64\bin\
```
将以上路径替换成你自己的 Qt 安装路径即可,一定不要搞错了。
然后准备好你的 Qt 路径和 MySQL 路径,在终端中分别执行以下四行命令:
```shell
cd C:\Qt\Qt5.14.2\5.14.2\Src\qtbase\src\plugins\sqldrivers
qmake -- MYSQL_INCDIR="C:\mysql-5.7.36-winx64\include" MYSQL_LIBDIR="C:\mysql-5.7.36-winx64\lib"
mingw32-make
mingw32-make install
```
上面的路径依然是我自己的路径,请务必更改为自己的 Qt 和 MySQL 路径!
执行完第二行命令后,正常情况会输出以下内容:
```
Info: creating stash file C:\Qt\Qt5.14.2\5.14.2\Src\qtbase\src\plugins\sqldrivers\.qmake.stash
Running configuration tests...
Checking for DB2 (IBM)... no
Checking for InterBase... no
Checking for MySQL... yes
Checking for OCI (Oracle)... no
Checking for ODBC... yes
Checking for PostgreSQL... no
Checking for SQLite (version 2)... no
Checking for TDS (Sybase)... no
Done running configuration tests.
Configure summary:
Qt Sql Drivers:
DB2 (IBM) .............................. no
InterBase .............................. no
MySql .................................. yes
OCI (Oracle) ........................... no
ODBC ................................... yes
PostgreSQL ............................. no
SQLite2 ................................ no
SQLite ................................. yes
Using system provided SQLite ......... no
TDS (Sybase) ........................... no
Qt is now configured for building. Just run 'mingw32-make'.
Once everything is built, you must run 'mingw32-make install'.
Qt will be installed into 'C:\Qt\Qt5.14.2\5.14.2\mingw73_64'.
Prior to reconfiguration, make sure you remove any leftovers from
the previous build.
```
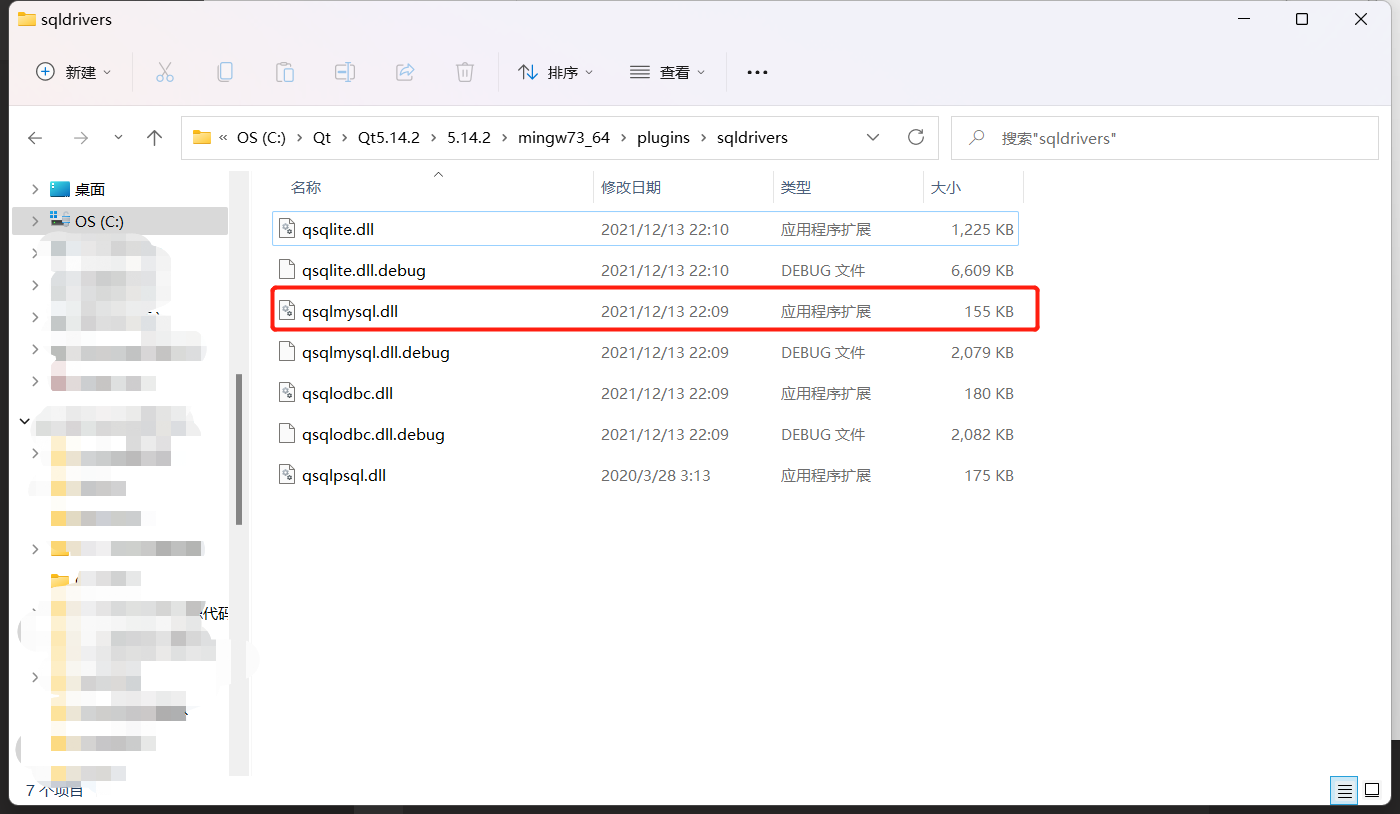
其中你需要关注你的 Checking for MySQL...后面和 Qt Sql Drivers 中的 MySql 是否都是 yes,如果不是,请检查你的路径和编译前的要求,无误后重新执行命令。
然后进行 make 和 install,中途可能会报一些 Warning,问题不大,只要命令执行完成后,你的 sqldrivers 文件夹中出现了如图所示的 qsqlmysql.dll 就代表编译完成了。
### Qt MySQL 驱动构建(使用 MSVC 编译套件)
#### 准备
与使用 `MinGW` 编译类似,不同的是在使用 QtCreator 配置这个项目时,需要选择对应版本的 MSVC 编译套件,这里以 Qt5.15.2 为例,首先打开 mysql 驱动的 Qt 工程文件:
```
C:\Qt\5.15.2\Src\qtbase\src\plugins\sqldrivers\mysql\mysql.pro
```
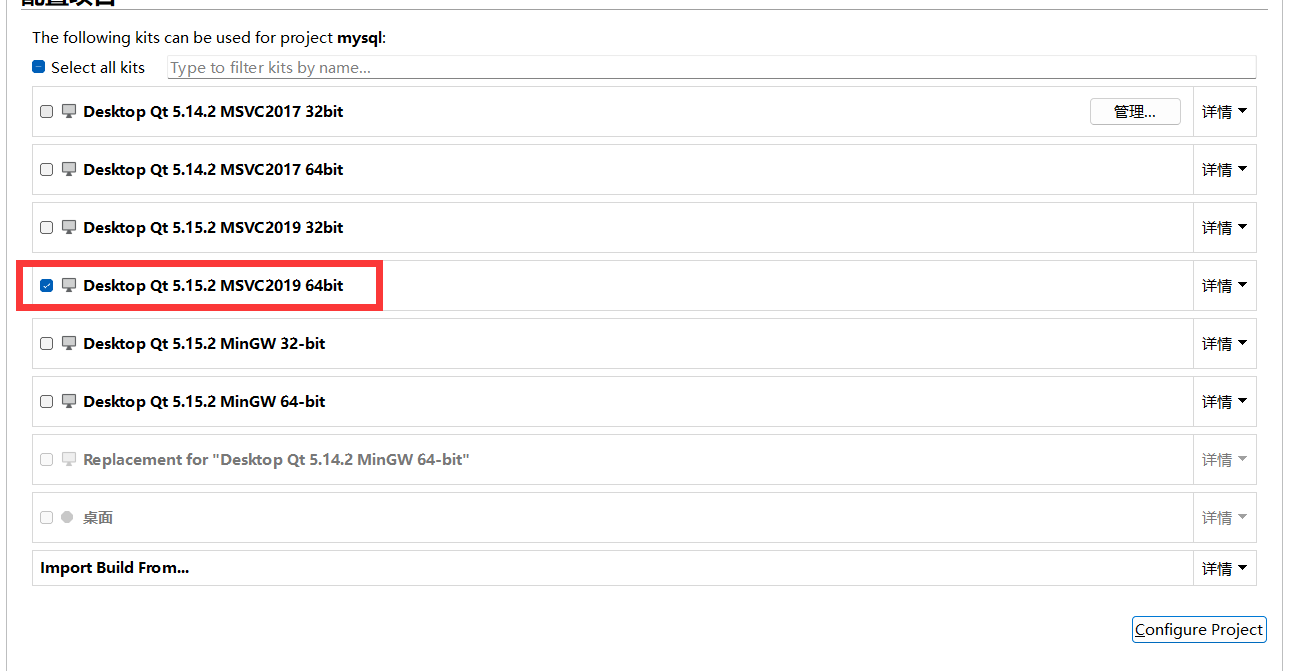
在这里我选择 `MSVC2019 64bit` (注意与自己的 Qt 版本对应,这里对应 Qt5.15.2),然后配置项目即可。
然后会出现一些 `error`,此时将 `mysql.pro` 文件中的部分代码修改为:
```
TARGET = qsqlmysql
HEADERS += $$PWD/qsql_mysql_p.h
SOURCES += $$PWD/qsql_mysql.cpp $$PWD/main.cpp
# QMAKE_USE += mysql 注释此处
#以下路径根据自己的mysql安装路径添加
LIBS += -LC:/mysql-5.7.36-winx64/lib -llibmysql
INCLUDEPATH += C:/mysql-5.7.36-winx64/include
DEPENDPATH += C:/mysql-5.7.36-winx64/include
OTHER_FILES += mysql.json
PLUGIN_CLASS_NAME = QMYSQLDriverPlugin
include(../qsqldriverbase.pri)
```
* `LIBS` 指定的本地 `mysql` 动态库路径和动态库的名字;
* `-L` 指定库的路径;
* `-l` 指定库的名字,不需要写后缀,对应的文件全名为 `libmysql.dll`;
* `INCLUDEPATH` 和 `DEPENDPATH` 指定的是本地 `mysql` 的头文件目录。
#### 编译
修改完成后,选择 Release 进行编译,会出现错误:`error: Cannot read C:/qtsqldrivers-config.pri: No such file or directory`,此时打开项目中 `qsqldriverbase.pri`文件:
```
# include($$shadowed($$PWD)/qtsqldrivers-config.pri) 注释此处
include(./configure.pri) # 添加本行
```
然后重新按上述方法编译即可,编译成功之后,就得到了该项目生成的库文件,库文件的位置在安装 Qt 所在盘符的 plugins 目录中。
* `qsqlmysql.dll` Release 版本的动态库
* `qsqlmysqld.dll` Debug 版本的动态库
### 最后
将 `mysql` 安装目录中的 `libmysql.dll` 放入你的 Qt 对应编译套件文件夹的 bin 目录或 exe 文件所在目录,MySQL 数据库即可成功连接,项目最终打包上线时,也别忘了将 libmysql.dll 打包进去。
也可以编辑 qmake 的.pro 文件,在其中把该链接库加进去,但打包时还是需要自行添加 libmysql.dll:
```
LIBS += "C:\mysql-5.7.36-winx64\lib\libmysql.dll"
# 或添加
LIBS += -LC:\mysql-5.7.36-winx64\lib\ -llibmysql
```
libmysql.dll 在你的 MySQL 目录下的 lib 文件夹内,不同版本也是不能混用,这里推荐 MySQL5.7。
其次,还需要将刚才我们编译好的驱动`qsqlmysql.dll`和`qsqlmysqld.dll`复制到以下路径:
```
C:\Qt\5.15.2\msvc2019_64\plugins\sqldrivers # 根据自己的版本选择对应路径
```
[tip type="info" title="参考内容"]https://subingwen.cn/qt/sql-driver/[/tip]
---
Henry 2021-12-13 **未经授权 禁止转载**
Java异常处理https://www.bytecho.net/archives/1878.html2021-10-26T09:30:00.000Z在程序中,错误可能产生于各种我们没有预料到的各种情况,在 Java 中这种在程序运行时可能出现的一些错误称为异常(Exception),了解 Java 中常见的异常有助于帮我们快速定位问题,提高开发效率。
Java 所有的异常都是由 Throwable 继承而来,其中 Error 比较严重是无法手动抛出异常的,一般情况下我们最关心的就是 Exception 这种非致命性异常。
### 捕捉异常
Java 的异常捕获结构由 `try`,`catch` 和 ` finally` 三部分组成,其中 `try` 语句块存放可能发生异常的 Java 语句;`catch` 在 `try` 之后,用来激发被捕获的异常;`finally` 语句块是异常处理结构的最后执行部分,如以下程序片段所示:
```java
try {
//可能抛出异常的语句
}
catch(exceptionType e) {
//对exceptionType异常进行处理的语句
}
catch(otherExceptionType e) {
//对其他异常的处理
}
//...
finally {
//...
}
```
由此可见,Java 异常处理大致分为 try-catch 语句块和 finally 语句块。当 try 代码块中的语句发生异常时,程序会跳转到 catch 代码块中执行,执行完毕后讲继续执行之后的代码,而不会执行 try 代码块中发生异常语句之后的代码,从而 Java 不会因为一个异常而影响整个程序的运行。
上面代码块中的 e 是一个对象,我们可以使用以下常用的成员函数来获取抛出异常的有关信息:
| 成员函数 | 说明 |
| ----------------- | ------------------------------------------------------------------------ |
| getMessage() | 输出错误性质 |
| toString() | 给出异常的类型与性质 |
| printStackTrace() | 指出异常的类型、性质、栈层次及出现在程序中的位置 |
### 常见异常
在 Java 中已经提供了很多异常来描述比较常见的错误,其中有的需要程序员进行捕获处理或声明来抛出,有的由 Java 虚拟机自动捕获处理,Java 常见的异常很多,因为大部分异常类名由我们很熟悉的单词组成,就不一一介绍其异常类的意义了。
| 异常类 | 说明 |
| ---------------------- | ------------------------- |
| ClassCaseException | 类型转换 异常 |
| ClassNotFoundException | 未找到对应类 异常 |
| ... | ... |
### 自定义异常
使用 Java 内置的异常类即可描述大部分异常情况,除此之外的异常,我们只需要继承 Exception 类即可自定义异常类:
```java
public class myException extends Exception {
public myException(String errorMessage) {
super(errorMessage);
}
}
```
以上代码片段中的 errorMessage 既是要输出的错误信息,如果我们想抛出自定义异常对象,则要使用 `throw` 关键字,此时程序在执行到 `throws` 时立即终止,其后面的语句将不会执行:
```java
public class study {
static int avg(int num_1, int num_2) throws myException {
if(...)
throws new myException("..."); //抛出的错误信息
if(...)
throws new myException("..."); //抛出的其他错误信息
return ...;
}
}
```
`throw` 关键字通常用于在 声明方法时指定该方法可能抛出的异常类型,多个异常可用逗号分隔,比如:
```java
public class Main {
static int avg(int num_1, int num_2) throws NegativeArraySizeException, ArrayIndexOutOfBoundsException {
//...
}
}
```
### RuntimeException
其次,Java 还提供了常见的 RuntimeException,这些异常同样可用通过 try-catch 语句捕获。
---
编辑:Henry 2021-10-26
等待小陌回归,近期有重磅消息,见评论区!https://www.bytecho.net/archives/moshanghua.html2021-10-20T13:40:00.000Z### 等待捞陌回归的第 4 个月:(敏感信息已屏蔽 *)
* 经过异步统计及日志历史数据分析,捞陌地址为 NaN,服务商为 NaN。
* IP:14.---.---.68 113.---.---.155 116.---.---.5 14.---.---.72 14.---.---.68 等...
* 系统:macOS、Windows10、Android 10,浏览器:Firefox。
* 近两周来未发现与以上信息大致相符及所有 NaN IP 的用户访问本站,哎,技术性调查以失败告终。
* 微信读书阅读(正常,无回应),QQ 音乐播放时长一周 1000 小时 +(异常,无回应),QQ 近两个月未上线(异常,无回应),支付宝有活动(正常,无回应),微信无任何活动(异常 *,无回应),xuanmo 渠道(无进展)
最终得出结论:各类分析不成立,无解!
### 致陌上花的一段话
> 2020 年对我来说是平淡的一年。2021 年我的展望也将是收尾的一年,重新规划的一年。
> 2021 希望可以活得更认真一点,能随我所愿,尽量让自己变得充实有趣起来,但说实话我也没什么信心。也希望我身边的每个人都能在 2020 年找到人生的方向,继续前行。
>
> ——《我的 2020》moshanghua
我和朋友们推测出许多可能性,最终也被文章开头的事实所推翻,我们不知道你现在究竟是什么情况,从七月到十月底,一晃都快半年了,你之前的规划也不知道你是否进行,但比起这个,我更想知道的是你现在是否是以积极的状态在生活,希望你能回归,更希望在这几个月里已经对未来有个更进一步的规划,别把自己隐藏起来::xhl:emoji_74::,人总是需要交流需要合作的。
### 再读曾经的 《我的 2020》
> @xiaomo#516 除了上班,下班就是回到住的地方自娱自乐着。
☹ 目前的工作其实也只能这样,毕竟工作时间太长了,但不能把什么都放在工作上,因为还有比它更重要的事,为了更好的工作。
> @xiaomo#516 如果想活就好好爱惜自己的身体!
这句话很重要,但我也没有做到。
> @xiaomo#516 重新拿起了前端的学习。但学习效率很低,缺乏大量练习而导致学的效果并不好,调整中。
不管是谁,不管有没有天赋,断断续续的学习总是不成体系的,大量练习的前提也是要有良好的基础,否则也是无从下笔,基础知识成体系地过一遍再练习会有巨大的收获,拿我上学期来说,其实我是没怎么复习的,毕竟在家学习,但其实成绩挺理想的(当然是我喜欢的科目),当你基础理论学习差不多的时候,适当的做个小项目,巩固你所学的大部分,这个效果比拿本书来复习好太多了,至少计算机行业是这样,计算机不再是高中纸上谈兵的学习,不是说比谁看的书多,我同学(学习委员)其他科目都很不错,唯独 C 语言五六十分,你说她不努力吗,说实话比我努力多了,可就是不懂的怎么学习,**事倍功半**当然也和我没得比,我永远相信学习有捷径可走,**不走弯路那就是学习最好的捷径**,努力有时候其实也不一定能成功,就是在这些地方做的没别人好。
> @xiaomo#516 目前工作还算稳定,但是自己明显感觉自己积极性变低
工作稳定不是现在的目的,现在所需的是**环境稳定**,不要有任何外界的事情来干扰自己,环境的如何,学习效果截然不同,如果把我放在一个专科?或者职高?周围都是浮躁的声音,一个个同学找你打游戏,出于人际关系,你可能无法拒绝(就像你公司聚餐一样),那显然是无法跟上你自己的进度的,我觉得环境是仅次于努力及方法的一个重要因素,名校不代表它的师资有多么优秀,而是代表它的生源非常优秀,一群优秀人才的聚集地,这才是名校出优生的真正原因,一定不要让自己目前并不满意的工作把自己的学习时间、环境压榨了,如果还想要去自己理想的行业就业的话。
> @xiaomo#516 珍惜眼前人
这句话非常好,能有一群良师益友,能让你更顺利得走出坎坷,我高中就是如此,其实这也是一种环境,珍惜对自己有帮助的人,少接触整天向你传输负能量的人,其实**很少有人愿意让你过得比他自己好**,唯独你的家人和你真正的朋友,这就是人性吧。
> @xiaomo#516 练一手字
练字很重要,能改变别人对你的第一印象,越早练习越好。书写对我来说是一种享受。
> @xiaomo#516 确定发展的方向,不在迷茫而不付诸行动
人还年轻,确定了就好好做,如果现在没信心做下去,其实以后你会更没信心!
> @xiaomo#516 多接触新鲜事物
大城市是一个开拓眼界的好地方,能接触到好多自己从没接触过的事物,这都是成长,不说为了自己,为了自己的后代,年轻人应该向大城市走,大小城市的教育资源问题我经常在讨论,在大城市高考和在小县城高考的名校率差别太大了,我们高中努力的人很多,考上名校的人有多少?这是个值得思考的问题。
### 未来?
最后,给你推荐个歌手——[司南](https://music.163.com/#/artist?id=28863695),我知道你喜欢银临,也喜欢听这类歌。我很喜欢她的声音,以后 【一起听】 歌单又能增加不少共同喜爱的歌了::xhl:tuodan::。
希望你早点回来,再大的困难都能过去,我也打算考完研转 Go 和前端了,希望你也对自己未来有了进一步的规划!
在负能量的环境里待多了,我愿意与任何有理想且真正热爱计算机的同学共同进步。
[button href="https://music.163.com/#/song?id=1446251992"]歌曲【奔赴】——司南[/button]
---
编辑:Henry 2021-10-20
时隔多年,终于摆脱了控制台https://www.bytecho.net/archives/1829.html2021-08-06T13:09:00.000Z学习 C++ 多年,都是游走在小黑框(终端)里,今天开始了 Qt 学习,给我很早以前的快速/归并排序做了图形界面。


学习各类高级语言,数据结构与算法,最终还得要有做项目的能力,一个像样的项目怎么能少的了图形界面。
---
Henry 2021-08-06
论内卷https://www.bytecho.net/archives/1822.html2021-07-24T08:43:00.000Z**鉴于整天把内卷挂嘴边的人如此之多,我建议每个人都仔细阅读此文!看看你周围人是不是文中所描述的那种人,再看看你自已又是不是?**
> 某种意义上来说,内卷只是弱者的借口词而已。
内卷真正说的是不理性的竞争,但现在却逐渐发展成了别人在努力,你却想躺平但又看见别人在努力而从心里上过不去,这时的你因内心的不平衡而想把你周围努力的人拉下水来让自己安心。你们所谓的“内卷”,以我看来,大概率是个人偏见下的低水平竞争,然而又被伪装成人人都不可避免的高端竞争。
如今一个个大学生,整天不是打游戏就是耍男女朋友,写写作业完成任务,临近期末抱佛脚而求不挂,考试前图书馆与教室满满的人奋笔疾书,这叫内卷吗?这只是自保罢了,内卷的前提是努力做好自己该做的事情来尽力得到属于自己的资源。当一个方向努力的人多了,但资源却没有改变,内卷现象这才产生,努力的人更加努力来争取有限的资源,内卷导致了个体“收益努力比”下降的现象。
我周围很多人整天都在说内卷内卷,其实他们大部分人的实力还达不到内卷的境界(同行间竞相付出更多努力以争夺有限资源那才叫内卷),那有多少人谈得上为自己所热爱而努力呢?把考试前的临时抱佛脚说成是内卷那真是可笑之极!**有时间去抱怨内卷还不如想想自己目前真正差的原因到底是社会上的内卷还是自身严重的惰性以及空洞的理想。**
没有理想何谈方向又何谈努力,整天安于现状只顾短暂的安定,优秀的人在为了未来而被迫内卷,而有的人还在为自己的一些如此简单的考试而担忧。还是那句话,很多人现阶段那水平还达不到与优秀者内卷的资格!当然,内卷并不是一件好事,但抱怨内卷前请先对得起自己。
喜欢的东西就要去努力争取,这样在我们失败的时候,就可以尽情地埋怨这个时代,而不必恼恨自己。
---
全文:Henry 2021-07-24 **未授权禁止转载!**
我的博客即将同步至腾讯云 + 社区,邀请大家一同入驻:https://cloud.tencent.com/developer/support-plan?invite_code=1fl7x472n9ep
堆排序https://www.bytecho.net/archives/1819.html2021-06-18T08:16:00.000Z输入一个长度为 $n$ 的整数数列,从小到大输出前 $m$ 小的数。
#### 输入格式
第一行包含整数 $n$ 和 $m$。
第二行包含 $n$ 个整数,表示整数数列。
#### 输出格式
共一行,包含 $m$ 个整数,表示整数数列中前 $m$ 小的数。
#### 数据范围
$\rm{1} \le m \le n \le {10^5}$
$\rm{1} \le 数列中的元素 \le {10^9}$
#### 输入样例
```
5 3
4 5 1 3 2
```
#### 输出样例
```
1 2 3
```
#### 题解
**(堆)** 完全二叉树 数据结构
如何手写一个堆?
| 操作 | 代码 |
| --------------------------- | ------------------------------------------------- |
| 插入一个数 | `heap[++size] = x; up(size);` |
| 求集合当中的最小值 | `heap[1];` |
| 删除最小值 | `heap[1] = heap[size]; size--; down(1);` |
| 删除任意一个元素 | `heap[k] = heap[size]; size--; down(k); up(k);` |
| 修改任意一个元素 | `heap[k] = x; down(k); up(k);` |
`up()` 函数 $O(logn)$:将当前元素与其父节点进行比较,若小于,则交换;
`down()` 函数 $O(logn)$:将当前元素与其左、右子节点进行比较,若大于,则交换。
#### C++ 代码
```cpp
#include <iostream>
#include <algorithm>
using namespace std;
const int N = 100010;
int n, m;
int heap[N], _size;
void down(int u)
{
int t = u;
if(u * 2 <= _size && heap[u * 2] <= heap[t])//与左节点比较
t = u * 2;
if(u * 2 + 1 <= _size && heap[u * 2 + 1] <= heap[t])//与右节点比较
t = u * 2 + 1;
if(u != t)
{
swap(heap[u], heap[t]);
down(t);//继续递归
}
}
int main()
{
cin >> n >> m;
for (int i = 1; i <= n; i++)//从1开始较为方便
cin >> heap[i];
_size = n;
for (int i = n >> 1; i; i--)//从倒数第二层开始down即可,最后一层不需要
down(i);
while(m--)
{
cout << heap[1] << ' ';//输出堆顶(最小元素)
heap[1] = heap[_size], _size--;//删除堆顶
down(1);
}
}
```
本题并不需要 `up()` 函数,故单独列出:
```cpp
void up(int u)
{
while(u / 2 && heap[u / 2] > heap[u])
{
swap(heap[u / 2], heap[u]);
u /= 2;
}
}
```
连通块中点的数量https://www.bytecho.net/archives/1818.html2021-06-14T08:30:00.000Z给定一个包含 $n$ 个点(编号为 $\rm{1} \sim {\rm{n}}$ )的无向图,初始时图中没有边。
现在要进行 $m$ 个操作,操作共有三种:
1. “C a b”,在点 $a$ 和点 $b$ 之间连成一条边,$a$ 和 $b$ 可能相等;
2. “Q1 a b”,询问点 $a$ 和点 $b$ 是否在同一连通块中,$a$ 和 $b$ 可能相等;
3. “Q2 a”,询问点 $a$ 所在连通块中点的数量。
#### 输入格式
第一行输入整数 $n$ 和 $m$。
接下来 $m$ 行,每行包含一个操作指令,指令为以上三种中的其中一种。
#### 输出格式
对于每个询问指令“Q1 a b”,如果$a$ 和 $b$ 在同一连通块中,则输出“Yes”,否则输入“No”。
对于每个询问指令“Q2 a”,输出一个整数表示点 $a$ 所在连通块中点的数量。
每个结果占一行。
#### 数据范围
$\rm{1} \le n,m \le {10^5}$
#### 输入样例
```
5 5
C 1 2
Q1 1 2
Q2 1
C 2 5
Q2 5
```
#### 输出样例
```
Yes
2
3
```
#### 题解
**(并查集)** 数据结构
具体实现同:[合并集合](https://www.bytecho.net/archives/1814.html)
#### C++ 代码
```cpp
#include <iostream>
using namespace std;
const int N = 100010;
int n, m;
int p[N], _size[N]; //size表示每一个集合的元素个数,只需根节点size有意义即可
int find(int x) //返回x所在集根节点 + 路径压缩优化
{
if (p[x] != x)
p[x] = find(p[x]);
return p[x];
}
int main()
{
cin.tie(0); //优化cin
ios::sync_with_stdio(false); //优化cin
scanf("%d%d", &n, &m);
for (int i = 1; i <= n; i++)
{
p[i] = i;//初始化,每个数各自在一个集合
_size[i] = 1;
}
while (m--)
{
char op[5];
int a, b;
cin >> op;
if(op[0] == 'C')
{
cin >> a >> b;
if(find(a) == find(b)) //如果a和b以及在同一个集合中,则不需要合并
continue;
_size[find(b)] += _size[find(a)]; //合并集合时,同时合并两个集合的元素个数
p[find(a)] = find(b);
}
else if(op[1] == '1')
{
cin >> a >> b;
find(a) == find(b) ? puts("Yes") : puts("No");
}
else
{
cin >> a;
printf("%d\n", _size[find(a)]);
}
}
return 0;
}
```
合并集合(并查集)https://www.bytecho.net/archives/1814.html2021-06-11T14:01:00.000Z一共有 $n$ 个数,编号是 $\rm{1} \sim n$,最开始每个数各自在一个集合中。
现在要进行 $m$ 个操作,操作共有两种:
1. “M a b”,将编号为 $a$ 和 $b$ 的两个数所在的集合合并,如果两个数已经在一个集合中,则忽略这个操作;
2. “Q a b”,询问编号为 $a$ 和 $b$ 的两个数是否在同一集合中。
#### 输入格式
第一行输入整数 $n$ 和 $m$。
接下来 $m$,每行包含一个操作指令,指令为“M a b”或“Q a b”其中一种。
#### 输出格式
对于每个询问指令“Q a b”,都要输出一个结果,如果 $a$ 和 $b$ 在同一集合内,则输出“Yes”,否则输出“No”。
每个结果占一行。
#### 数据范围
$\rm{1} \le n,m \le {10^5}$
#### 输入样例
```
4 5
M 1 2
M 3 4
Q 1 2
Q 1 3
Q 3 4
```
#### 输出样例
```
Yes
No
Yes
```
#### 题解
**(并查集)** 数据结构
并查集介绍:
1. 将两个集合合并
2. 询问两个元素是否在一个集合当中
基本原理:每个集合用一棵树来表示,树根的编号就是整个集合的编号,每个节点存储它的父节点,p[x]表示 x 的父节点。
问题 1:如何判断树根:`if(p[x] == x)`;
问题 2:如何求 x 的集合编号:`while(p[x] != x) x = p[x];`;
问题 3:如何合并两个集合:p[x]是 x 集合编号,p[y]是 y 的集合编号,`p[x] = y;`
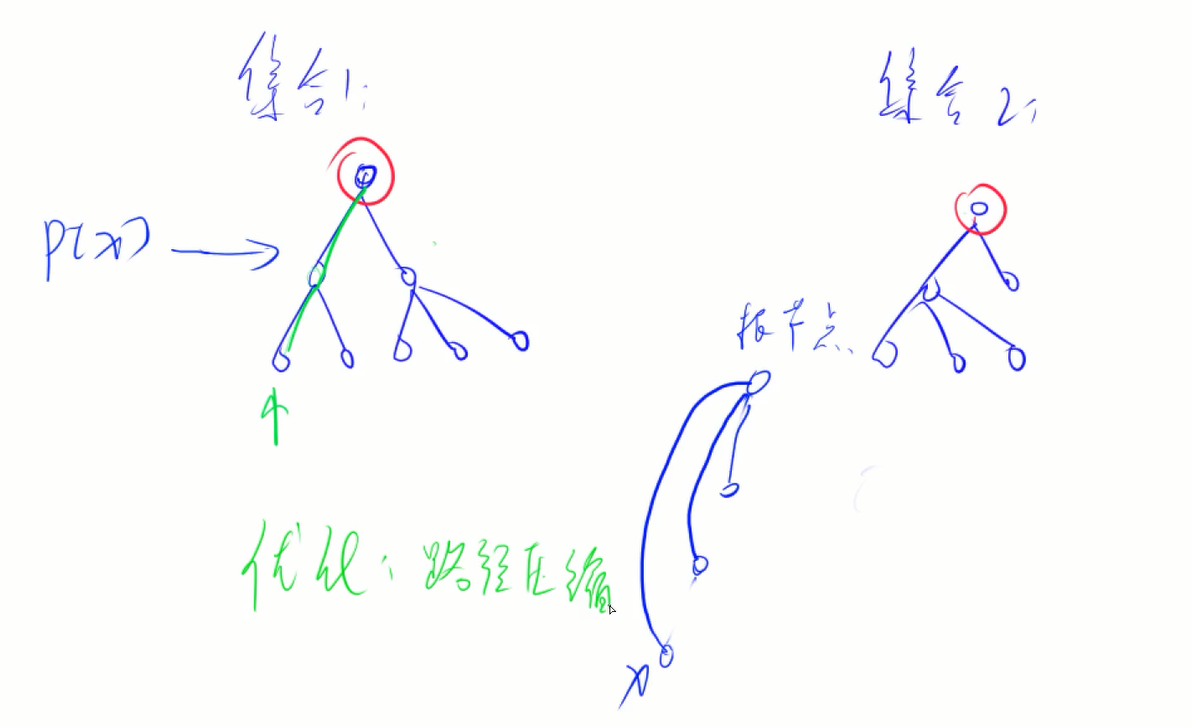
!!!
<center>图1 [并查集及其路径压缩优化] 闫学灿</center>
!!!
#### C++ 代码
```cpp
#include <iostream>
using namespace std;
const int N = 100010;
int n, m;
int p[N];
int find(int x) //返回x所在集根节点 + 路径压缩优化
{
if (p[x] != x)
p[x] = find(p[x]);
return p[x];
}
int main()
{
scanf("%d%d", &n, &m);
for (int i = 1; i <= n; i++)
p[i] = i;//初始化,每个数各自在一个集合
while (m--)
{
char op[2];
int a, b;
cin >> op >> a >> b;
if(op[0] == 'M')
p[find(a)] = find(b);
else
find(a) == find(b) ? puts("Yes") : puts("No");
}
return 0;
}
```
Trie字符串统计https://www.bytecho.net/archives/1812.html2021-06-11T12:23:00.000Z维护一个字符串集合,支持两种操作:
1. “I x”向集合中插入一个字符串 $x$;
2. “Q x”询问一个字符串在集合中出现了多少次。
共有 $N$ 个操作,输入的字符串总长度不超过 $\rm{10^5}$,字符串仅包含小写英文字母。
#### 输入格式
第一行包含整数 $N$,表示操作数。
接下来 $N$ 行,每行包含一个操作指令,指令为“I x”和“Q x”中的一种。
#### 输出格式
对于每个操作指令“Q x”,都要输出一个整数作为结果,表示 $x$ 在集合中出现的次数。
每个结果占一行。
#### 数据范围
$\rm{1} \le N \le 2*{10^4}$
#### 输入样例
```
5
I abc
Q abc
Q ab
I ab
Q ab
```
#### 输出样例
```
1
0
1
```
#### 题解
**(Trie 树)** 数据结构
插入操作:
从根节点开始,枚举当前字符串,如果对应字母节点存在,则进入下一个节点,否则创建节点。字符串枚举完成后,创建当前节点单词结尾标记。
查询操作:
同插入操作,如果任意一个字母节点不存在,则意味着该字符串一定不存在,否则继续枚举,最终范围尾节点的单词结尾标记。
#### C++ 代码
```cpp
#include <iostream>
using namespace std;
const int N = 100010;
int son[N][26];//子节点最多26个(26个英文字母)
int cnt[N], idx;//下标为0的点即是根节点,又是空节点,cnt为以当前点结尾的单词数量,idx表示当前可用的节点
char str[N];
void insert(char str[])
{
int p = 0;
for (int i = 0; str[i]; i++)
{
int u = str[i] - 'a';//转化为字母顺序
if(!son[p][u])//如果节点不存在,则创建
son[p][u] = ++idx;
p = son[p][u];//进入下一个点,即子节点
}
cnt[p]++;//单词结尾标记
}
int query(char str[])
{
int p = 0;
for (int i = 0; str[i]; i++)
{
int u = str[i] - 'a';
if(!son[p][u])
return 0;//中途有一个点不存在,就不存在
p = son[p][u];
}
return cnt[p];//返回单词结尾标记,即以该节点结尾的单词数量
}
int main()
{
int n;
cin >> n;
while(n--)
{
char op[2];
scanf("%s%s", op, str);
if(op[0] == 'I')
insert(str);
else
cout << query(str) << endl;
}
return 0;
}
```
KMP字符串https://www.bytecho.net/archives/1801.html2021-06-09T07:23:00.000Z给定一个模式串 $S$,以及一个模板串 $P$,所有字符串中只包含大小写英文字母以及阿拉伯数字。
模板串 $P$ 在模式串 $S$ 中多次作为字串出现。
求出模板串 $P$ 在模式串 $S$ 中所有出现的位置的起始下标。
#### 输入格式
第一行输出整数 $N$,表示字符串 $P$ 的长度。
第二行输入字符串 $P$。
第三行输入整数 $M$,表示字符串 $S$ 的长度。
第四行输入字符串 $M$。
#### 输入格式
共一行,输出所有出现位置的起始下标(下标从 $\rm{0}$ 开始计数),整数之间用空格隔开。
#### 数据范围
$\rm{1} \le N \le 10^4$
$\rm{1} \le M \le 10^5$
#### 输入样例
```
3
aba
5
ababa
```
#### 输出列表
```
0 2
```
#### 题解
**(KMP)** $O(m+n)$
KMP 算法是 D.E.Knuth、J,H,Morris 和 V.R.Pratt 三位神人共同提出的,称之为 Knuth-Morria-Pratt 算法,简称 KMP 算法。该算法相对于 Brute-Force(暴力)算法有比较大的改进,主要是消除了主串指针的回溯,从而使算法效率有了某种程度的提高。
KMP 算法的关键就是求 next 数组:
next 数组长度与字符串长度一致,每个位置存储对应字符的最长匹配长度。
next 数组即 `next[i] = length`; 长度为 $i$ 的数组的**前缀和后缀相等**的最大长度。 例如 $abcdeabc$ 就是 `next[8] = 3`; 相等的前缀和后缀最长是 $abc$ 长度为 $\rm{3}$。
为了更透彻理解 next 数组,我们来举一个**例子**:
模板串 $P$ 为:$abababab$(令其下标从 $\rm{1}$ 开始)
`next[1]` 即模板串中取长度为 $\rm{1}$ 的串,如果匹配失败,则退回到起点,故 `next[1]=0`;
`next[2]` 即模板串中取长度为 $\rm{2}$ 的串,显然其前缀 $a$ 和后缀 $b$ 不相等,故 `next[2]=0`;
`next[3]` 即模板串中取长度为 $\rm{3}$ 的串,其前缀 $a$ 和后缀 $a$ 相等,$a$ 的长度为 $\rm{1}$,故 `next[3]=1`;
$$
\vdots
$$
`next[6]` 即模板串中取长度为 $\rm{6}$ 的串($ababab$),其前缀 $abab$ 和后缀 $abab$ 相等,该字串长度为 $\rm{4}$ ,故 `next[6]=4`,以此类推,`next[7]=5`。
到此,我们应该明白 next 数组的意义了,现在我们加上模式串 $S$ 来看,假设 $S$ 为:$abababcab$(同样令其下标从 $\rm{1}$ 开始),以下矩阵代表当前两个字符串的对应关系:
$$
\left[ \begin{array}{l}
{\rm{a b a b a b c a b}}\\
{\rm{a b a b a b a b x}}
\end{array} \right]
$$
($x$ 代表空格),可见在 s[7] 时 $c$ 与 模板串 p[j + 1] 中 $a$ 不匹配,此时,我们如果令 `j = next[j]`,当前 $j=6$ 令 `j=next[j]=4` 后会发生什么,请看矩阵:
$$
\left[ \begin{array}{l}
{\rm{a b a b a b c a b x x x}}\\
{\rm{x x a b a b a b a b x x}}
\end{array} \right]
$$
为什么要这样操作?
因为我们 `next[i]` 长度为 $i$ 的数组的**前缀和后缀相等**的最大长度,刚才我们已经判断得到 p[1] $ \sim$ p[6] 一定是和 s[1] $\sim$ s[6] 完全匹配的,又因为 `next[i]=4`,故 p[1] $ \sim$ p[6]的前 $\rm{4}$ 个字符与后 $\rm{4}$ 个字符是完全相同的,也就得到 p[1] $ \sim$ p[4] 与 p[3] $ \sim$ p[6]完全相同,则 p[1] $ \sim$ p[4] 也与 s[3] $ \sim$ s[6] 完全相同(因为 p[1] $ \sim$ p[6] 和 s[1] $\sim$ s[6] 完全匹配),所以我们就没必要再从 p[1] 开始枚举,直接从 p[4 + 1]开始即可。
这样操作我们就省去了主串指针的回溯所花费的不必要的时间,接下来的步骤以此类推,详见 C++ 代码部分的 kmp 匹配过程。
#### C++ 代码
```cpp
#include <iostream>
using namespace std;
const int N = 10010, M = 100010;
int n, m;
char p[N], s[M];
int ne[N]; //next数组
int main()
{
cin >> n >> (p + 1) >> m >> (s + 1); //下标从1开始
//求next数组过程
for (int i = 2, j = 0; i <= n; i++)//i从2开始即可,i=1不匹配的话即是退为0,不考虑
{
while(j && p[i] != p[j + 1])
j = ne[j];
if(p[i] == p[j + 1])
j++;
ne[i] = j;
}
//kmp匹配过程
for (int i = 1, j = 0; i <= m; i++)
{
while (j && s[i] != p[j + 1]) //j未回退到起点,且当前不匹配
j = ne[j]; //ne[j]表示p[j+1]前端和s匹配的最小移动坐标
if (s[i] == p[j + 1])
j++;
if (j == n)
{
printf("%d ", i - n);//起始下标
j = ne[j];
}
}
return 0;
}
```
滑动窗口(单调队列)https://www.bytecho.net/archives/1800.html2021-06-08T15:24:00.000Z给定一个大小为 $n \le 10^6$ 的数组。
有一个大小为 $k$ 的滑动窗口,它从数组的最左边移动到最右边。
你只能在窗口中看到 $k$ 个数字。
每次滑动窗口向右移动一个位置。
以下是一个例子:
该数组为 $\left\{ {1,3, - 1, - 3,5,3,6,7} \right\}$,$k$ 为 $\rm{3}$。
| 窗口位置“[]”区域 | 最小值 | 最大值 |
| ------------------- | --------- | --------- |
| [1 3 -1] -3 5 3 6 7 | -1 | -3 |
| 1 [3 -1 -3] 5 3 6 7 | -3 | 3 |
| 1 3 [-1 -3 5] 3 6 7 | -3 | 5 |
| 1 3 -1 [-3 5 3] 6 7 | -3 | 5 |
| 1 3 -1 -3 [5 3 6] 7 | 3 | 6 |
| 1 3 -1 -3 5 [3 6 7] | 3 | 7 |
#### 输入格式
输入包含两行。
第一行包含两个整数 $n$ 和 $k$ ,分别代表数组的长度和滑动窗口的长度。
第二行有 $n$ 个整数,代表数组的具体数值。
同行数据之间用空格隔开。
#### 输出格式
输出包含两个。
第一行输出,从左至右,每个位置滑动窗口中的最小值。
第二行输出,从左至右,每个位置滑动窗口中的最大值。
#### 输入样例
```
8 3
1 3 -1 -3 5 3 6 7
```
#### 输出样例
```
-1 -3 -3 -3 3 3
3 3 5 5 6 7
```
#### 题解
**(单调队列)** 数据结构
数组模拟队列,类似于单调栈,将不满足单调性的元素弹出队列,构造单调队列,队头即为我们需要的极值。
#### C++ 代码
```cpp
#include <iostream>
using namespace std;
const int N = 1000010;
int n, k;
int a[N], q[N];//a为数组,q为队列
int main()
{
scanf("%d%d", &n, &k);//数据量大请使用scanf,比cin快很多
int hh = 0, tt = -1;
for (int i = 0; i < n; i++)
scanf("%d", &a[i]);
for (int i = 0; i < n; i++)//最小值情况
{
//判断队头是否已经弹出窗口
if(hh <= tt && i - k + 1 > q[hh])//i-k+1为当前窗口起点,此题最多有一次该情况,故写if,否则使用while
hh++;
while(hh <= tt && a[q[tt]] >= a[i])
tt--;
q[++tt] = i;//当前值压入队列
if(i >= k - 1)
printf("%d ", a[q[hh]]);
}
puts("");
hh = 0, tt = -1;
for (int i = 0; i < n; i++)//最大值情况
{
//判断队头是否已经弹出窗口
if(hh <= tt && i - k + 1 > q[hh])//i-k+1为当前窗口起点
hh++;
while(hh <= tt && a[q[tt]] <= a[i])
tt--;
q[++tt] = i;//当前值压入队列
if(i >= k - 1)
printf("%d ", a[q[hh]]);
}
return 0;
}
```
单调栈https://www.bytecho.net/archives/1796.html2021-06-08T10:17:00.000Z给定一个长度为 $n$ 的整数数列,输出每个数左边第一个比它小的数,如果不存在则输出 $-1$。
#### 输入格式
第一行包含整数 $N$,表示数列长度。
第二行包含 $N$ 个整数,表示整数数列。
#### 输出格式
共一行,包含 $N$ 个整数,其中第 $i$ 个数表示第 $i$ 个数的左边第一个比**它**小的数,如果不存在则输出 $-1$。
#### 数据范围
$\rm{1} \le N \le 10^5$
$\rm{1} \le 数列中的元素 \le 10^9 $
#### 输入样例
```
5
3 4 2 7 5
```
#### 输出样例
```
-1 3 -1 2 2
```
#### 题解
**(单调栈)** 数据结构 $O(n)$
栈即为先进后出的存储方式,先存储的数据最后弹出。
单调栈即为按照存储顺序,其元素具有严格单调性的栈。
要建立单调栈,就此题而言,从当前栈顶(当前栈中 $x$ 即将为栈顶)在 $x$ 入栈之前之前开始,如果栈不为空且比当前 $x$ 大,那么就将其弹出,结束循环后,若栈非空则代表存在该数,将其输出,反之输出 $-1$。
#### C++ 代码
```cpp
#include <iostream>
using namespace std;
const int N = 100010;
int n;
int stk[N], tt;
int main()
{
ios::sync_with_stdio(false);//优化cin效率
cin >> n;
for (int i = 0; i < n; i++)
{
int x;
cin >> x;
while(tt && stk[tt] >= x)//栈非空,且大于x,则弹出
tt--;
if(tt)
cout << stk[tt] << " ";
else
cout << "-1 ";
stk[++tt] = x;
}
return 0;
}
```
数组模拟的双链表https://www.bytecho.net/archives/1794.html2021-06-08T09:10:00.000Z实现一个双链表,双链表初始为空,支持 $\rm{5}$ 种操作:
1. 在最左侧插入一个数;
2. 在最右侧插入一个数;
3. 将第 $k$ 个插入的数删除;
4. 在第 $k$ 个插入的数左侧插入一个数;
5. 在第 $k$ 个插入的数右侧插入一个数
现在要对该链进行 $M$ 次操作,进行完所有操作后,从左到右输出整个链表。
**注意**:题目中第 $k$ 个插入的数并不是指当前链表的第 $k$ 个数,是按插入时间的第 $k$ 个数。
#### 输入格式
第一行包含整数 $M$,表示操作次数。
接下来 $M$ 行,每行包含一个操作命令,操作命令分为:
1. "L x",表示在链表的最左端插入数 $x$;
2. "R x",表示在链表的最右端插入数 $x$;
3. "D k",表示将第 $k$ 个插入的数删除;
4. "IL k x",表示在第 $k$ 个插入的数的左侧插入数 $x$;
5. "IR k x",表示在第 $k$ 个插入的数的右侧插入数 $x$
#### 输出格式
共一行,将整个链表从左到右输出。
#### 数据范围
$\rm{1} \le M \le \rm{100000}$
所有操作保证合法。
#### 输入样例
```
10
R 7
D 1
L 3
IL 2 10
D 3
IL 2 7
L 8
R 9
IL 4 7
IR 2 2
```
#### 输出样例
```
8 7 7 3 2 9
```
#### 题解
**(双链表)** 数据结构
单链表由于太过于基础,不再介绍!在**算法试题**中,往往使用数组模拟链表,因为C++ 中 `new()` 操作时间较长,容易超时;但在**工程中**,需要动态分配资源。具体实现方式已通过代码注释给出。
#### C++ 代码
```cpp
#include <iostream>
using namespace std;
const int N = 100010;
int m;
int e[N], l[N], r[N], idx;
//初始化,0为左端点,1为右端点
void init()
{
r[0] = 1, l[1] = 0;
idx = 2;
}
//在k的右边插入,若需要在k左边插入,则将k改为 l[k]
void add(int k, int x)
{
e[idx] = x;
l[idx] = k, r[idx] = r[k]; //操作新节点的左右指针
l[r[k]] = idx, r[k] = idx; //操作左右两边节点的指针
idx++;
}
//删除
void remove(int k)
{
r[l[k]] = r[k];
l[r[k]] = l[k];
}
int main()
{
init();
int m;
cin >> m;
while(m --)
{
string s;
cin >> s;
if(s == "L" || s == "R")
{
int x;
cin >> x;
s == "L" ? add(0, x) : add(l[1],x);
}
else if(s == "IL" || s == "IR")
{
int k, x;
cin >> k >> x;
s == "IL" ? add(l[k + 1], x) : add(k + 1, x);//idx从2开始,则第一个插入的数的idx为1+1,第k个就是k+1
}
else
{
int k;
cin >> k;
remove(k + 1);//idx从2开始,则第一个插入的数的idx为1+1,第k个就是k+1
}
}
for (int i = r[0]; i != 1; i = r[i]) //从左端点0的下一位开始输出,1为右端点,i到右端点停止
cout << e[i] << " ";
return 0;
}
```